
上期介绍了通过《mitmproxy实战-通过mitmdump爬取京东金榜数据》,能够上京东金榜的商品一般评价都是比较好的,这次介绍如何爬取京东商品的评价信息。
一、分析商品评价的页面信息#
1、请求参数分析#
京东的商品评价信息是在商品的详情页面,我们随便访问一个京东的商品详情页面如https://item.jd.com/100087971268.html
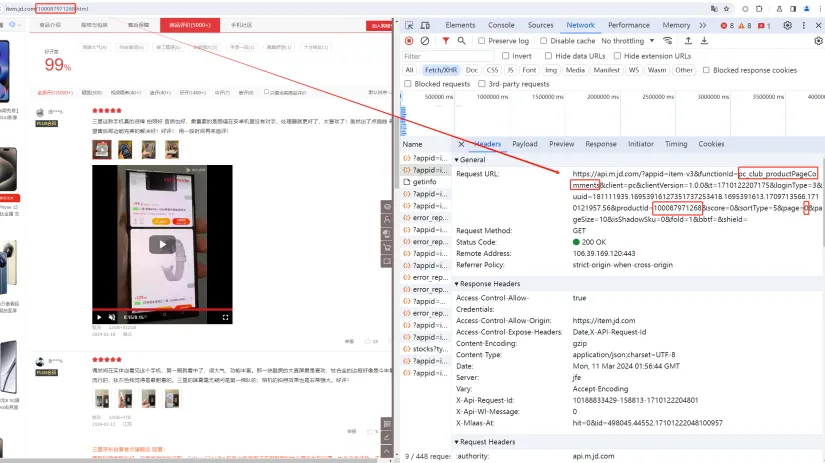
在这里可以看到100087971268就是商品ID也是商品的skuId,这个是商品的唯一ID可以和很过信息关联。我们可以通过chrome浏览器的调试模式来分析商品评价信息的数据是如何获取和展示的。
通过chrome浏览器的调试模式可以看到,评价信息是通过https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1710122207175&loginType=3&uuid=181111935.16953916127351737253418.1695391613.1709713566.1710121957.56&productId=100087971268&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield=
这个接口来返回的,其中关键的信息包括functionId=pc_club_productPageComments,productId=100087971268,page=0&pageSize=10。
productId=100087971268表示是获取商品ID为100087971268的商品评价,page=0&pageSize=10表示当前页是0,每页显示10条记录。
2、接口返回信息分析#
我们可以切换到Response的标签页,分析接口的返回信息
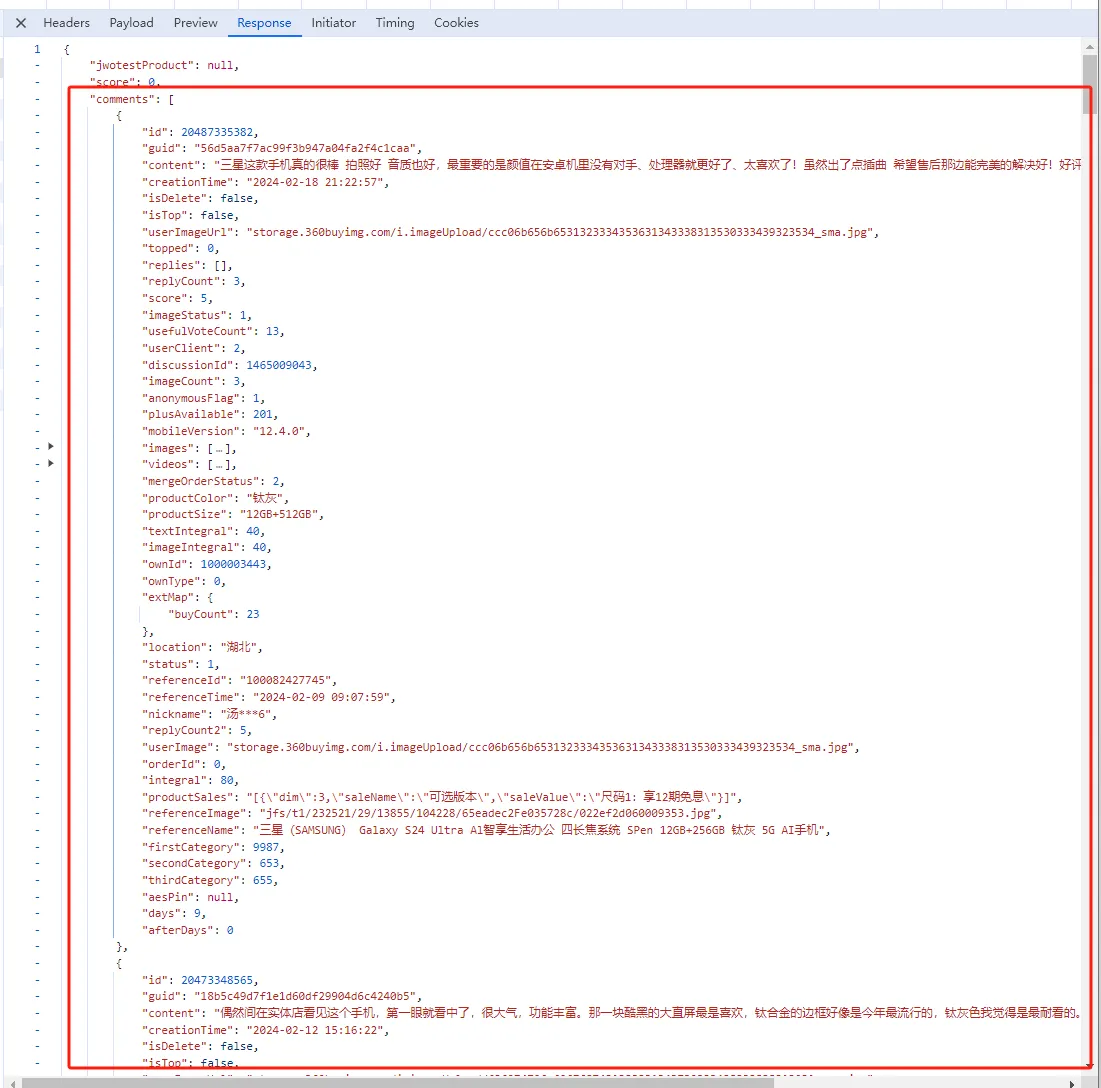
在这里可以看到通过接口反馈的是一个json格式的数据,其中评价信息就在comments的节点里,我们只要解析这个json就可以得到具体的评价信息了。
通过参数的分析和返回结果的分析后,就可以开始编码实现了。
二、爬取京东商品评价信息代码实现#
编码主要实现两个部分的内容
1、是要组织请求参数,将请求URL的一些参数用变量替换,如商品ID,当前页等。
2、是要解析返回的JSON数据,从JSON数据中解析获取需要的评价信息以及下载评价信息中的图片。
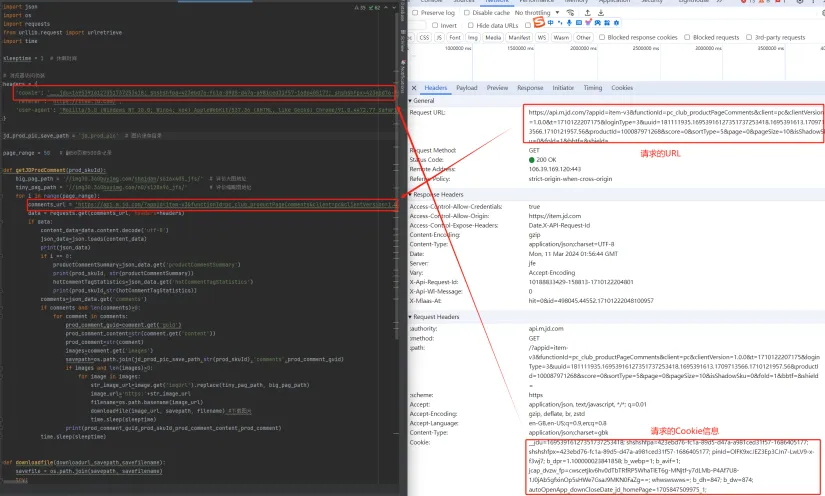
在组织请求参数的时候,有两个关键信息,一个是Cookie信息,一个是请求的URL,因为访问京东的接口要登录,所以需要Cookie的信息。这些信息都可以在登录到京东后在chrome浏览器的调试模式中可以拿到。
1、具体代码#
具体代码如下:
getJDProdComments.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| import json
import os
import requests
from urllib.request import urlretrieve
import time
sleeptime = 1 # 休眠时间
# 浏览器访问伪装
headers = {
'cookie': '___jdu=16953916127351737253418; shshshfpa=423ebd76-fc1a-89d5-d47a-a981cedfdsf57-1686fds5177; shshshfpx=423ebd76-fc1a-89d5-d47a-a981ced31f57-1686405177; pinId=OlFK9xcJEZ3Ep3CJn7-LwLV9-x-f3wj7; pin=jd_5ab1043c91fdff; unick=xiejava; _tp=xRz2UIA0gXgQ0KtQA8IW%2BhMgOusl53MovCk%2FP0TxaIM%3D; _pst=jd_5ab1043c91bff; PCSYCityID=CN_430000_430100_0; areaId=18; ipLoc-djd=18-1482-48942-49058; b_dh=1179; b_dpr=1.100000023841858; b_webp=1; b_avif=1; autoOpenApp_downCloseDate_auto=1705396790105_1800000; b_dw=1555; __jdv=91748099|baidu|-|organic|notset|1705397493195; jsavif=1; mba_muid=16953916127351737253418; wlfstk_smdl=4d5qhwajihbur3xtxm1dghq2bwl9ebii; 3AB9D23F7A4B3C9B=ONVXQU6KOVA46KLMDJWYJ2CLCGZLCKH4NFEKT6ANBHIYQJBOWM3KHFJ3RT5NO6GKP2BQVONOJWLAKMJUMNJOAMEHJE; TrackID=1wLmzwr1GPygNiM7hoidalzvJbkLlnJRs7c_e2wlsv7h_VHaLyqnXTiW1_vIDBhlEusopAT977EO67KV2n2vMV9jMUQx8MO9jJQMMv8skxrE; thor=C1CD4973B7F47EE1FE45201B5AB2281DC485D58F5BD12AA8CEC6335A9B07F5E3F1BFD9D9DEA859A32AEDE0F33C45B55AA44327ACD87A8E174C645BE4BC987735B3DD969561D2D0AA492DD1FEC1A793AF265724B02F9850F35F0CA58E8E4A5A3C212B0734C80AD560D299EC59026506C127E953C92D271932DDDBF32BEC59091745A6CB143671358CC8A866B9A298AA865F60B9AC41AD05C6EB6781C131BD05DD; flash=2_7Kqrs87KZ1MjgKXGB8QJTs9NjTmYiJCdEV8xYwXCMezATHn-bD7kirFJuQx5ogyzo_yuQHefS-MTOx8D5rxn-5ZxA8-qMHyBfYw-1ULH1bq*; ceshi3.com=103; __jdc=181111935; token=7482844f43473090375d99ad860b4294,3,947486; __tk=mLVlrKTimJznoD3PmcVvYmZmldTlkbVaommnjmTankZOmmPDolZTZmTfSJvkYRmblDzYrLKC,3,947486; shshshsID=a8f2acdf15967d81d4c5d8b5a45b7796_1_1705476526446; 3AB9D23F7A4B3CSS=jdd03ONVXQU6KOVA46KLMDJWYJ2CLCGZLCKH4NFEKT6ANBHIYQJBOWM3KHFJ3RT5NO6GKP2BQVONOJWLAKMJUMNJOAMEHJEAAAAMNCZJJB5QAAAAAD26SPFPWINAFQMX; _gia_d=1; shshshfpb=BApXeNARaFehAyBNmDl1nYWazwPZ1Fa6NB8QBVlhW9xJ1Mt5if4S2; __jda=181111935.16953916127351737253418.1695391613.1705471486.1705476528.12; __jdb=181111935.1.16953916127351737253418|12.1705476528; joyya=1705472508.1705476529.27.0u3hno2',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37',
}
jd_prod_pic_save_path = 'jd_prod_pic' # 图片保存目录
page_range = 50 # 翻50页取500条记录
def getJDProdComment(prod_skuId):
big_pag_path = '//img30.360buyimg.com/shaidan/s616x405_jfs/' # 评价大图地址
tiny_pag_path = '//img30.360buyimg.com/n0/s128x96_jfs/' # 评价缩略图地址
for i in range(page_range):
comments_url = 'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1705853247039&loginType=3&uuid=181111935.16953916127351737253418.1695391613.1705847111.1705852812.35&productId='+str(prod_skuId)+'&score=0&sortType=5&page='+str(i)+'&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='
data = requests.get(comments_url, headers=headers)
if data:
content_data=data.content.decode('utf-8')
json_data=json.loads(content_data)
print(json_data)
if i == 0:
productCommentSummary=json_data.get('productCommentSummary')
print(prod_skuId, str(productCommentSummary))
hotCommentTagStatistics=json_data.get('hotCommentTagStatistics')
print(prod_skuId,str(hotCommentTagStatistics))
comments=json_data.get('comments')
if comments and len(comments)>0:
for comment in comments:
prod_comment_guid=comment.get('guid')
prod_comment_content=str(comment.get('content'))
prod_comment=str(comment)
images=comment.get('images')
savepath=os.path.join(jd_prod_pic_save_path,str(prod_skuId),'comments',prod_comment_guid)
if images and len(images)>0:
for image in images:
str_image_url=image.get('imgUrl').replace(tiny_pag_path, big_pag_path)
image_url='https:'+str_image_url
filename=os.path.basename(image_url)
downloadfile(image_url, savepath, filename) #下载图片
time.sleep(sleeptime)
print(prod_comment_guid,prod_skuId,prod_comment_content,prod_comment)
time.sleep(sleeptime)
def downloadfile(downloadurl,savepath,savefilename):
savefile = os.path.join(savepath, savefilename)
try:
if not os.path.exists(savepath):
os.makedirs(savepath)
# 判断文件是否存在,如果不存在则下载
if not os.path.isfile(savefile):
print('Downloading data from %s' % downloadurl)
urlretrieve(downloadurl, filename=savefile)
print('\nDownload finished!')
else:
print('File already exsits!')
# 获取文件大小
filesize = os.path.getsize(savefile)
# 文件大小默认以Bytes计, 转换为Mb
print('File size = %.2f Mb' % (filesize / 1024 / 1024))
except Exception as e:
print('downloadfile Error:', e)
if __name__ == '__main__':
getJDProdComment('100087971268')
|
以上代码中的Cookie信息,需要根据自己登录后从chrome浏览器的调试模式中拿到的Cookie信息替换。
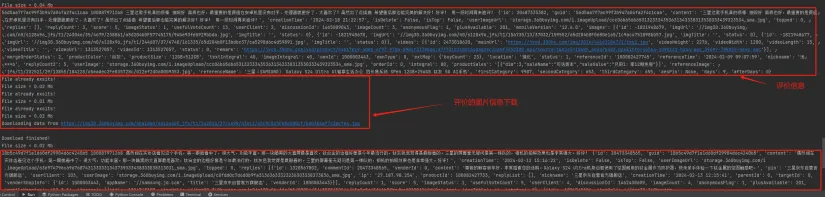
2、运行效果#
运行效果:
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!