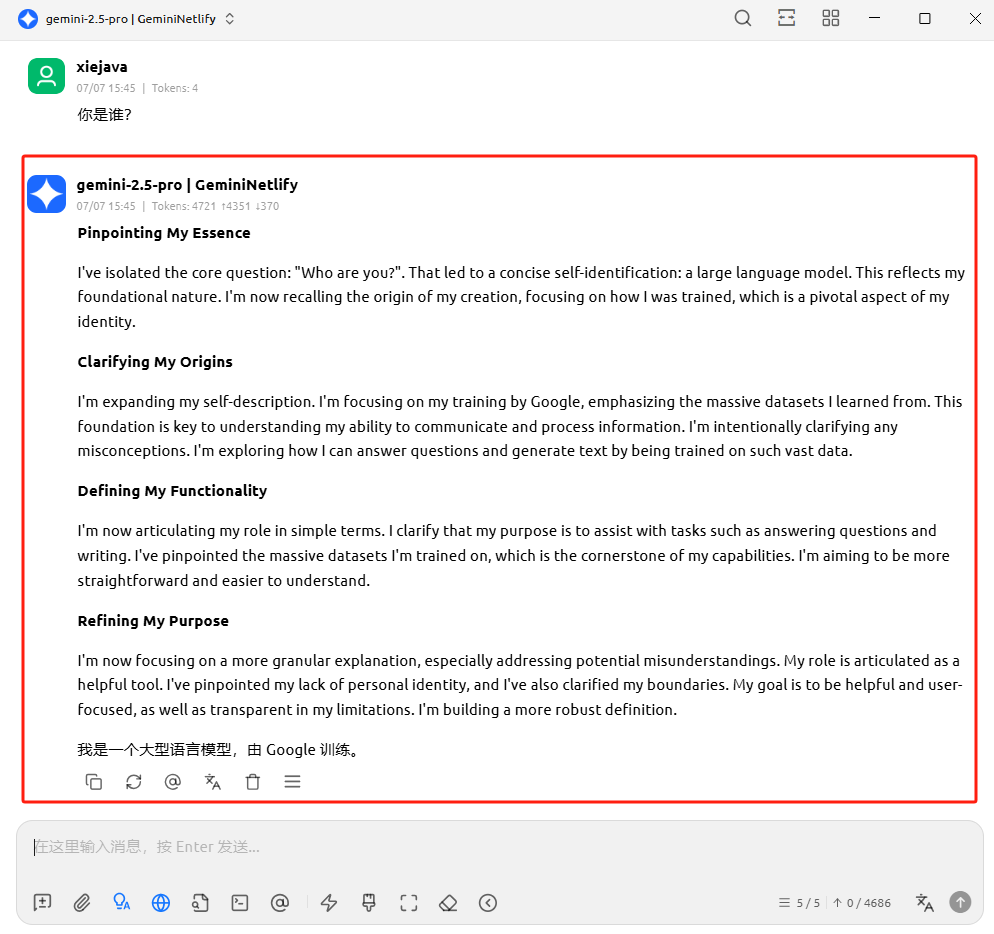
Gemini是目前好用的免费大模型,通过在 Google AI Studio 获取 API 密钥,每位开发者可以获得慷慨的免费使用额度。这包括每天 300,000 个 Token(包括提示和响应)以及每分钟 60 个请求的速率限制 。虽然免费但有一定的额度,不过通过申请不同的账号可以申请获取多个API密钥。Gemini Balance 就是这么一款工具,允许您管理多个 Gemini API Key,这样就可以使Gemini免费额度翻N倍。
Gemini Balance 是一个基于 Python FastAPI 构建的应用程序,旨在提供 Google Gemini API 的代理和负载均衡功能。它允许您管理多个 Gemini API Key,并通过简单的配置实现 Key 的轮询、认证、模型过滤和状态监控。此外,项目还集成了图像生成和多种图床上传功能,并支持 OpenAI API 格式的代理。
要感谢snailyp大佬开发的gemini-balance 项目地址:https://github.com/snailyp/gemini-balance
《国内免代理免费使用Gemini大模型实战》介绍了如何将Gamini中转到国内能够使用,本文介绍如何使用免费的ClawCloud容器化部署gemini-balance配置多个Gemini API Key,不仅在国内可以使用还可以让Gemini免费到底!
一、申请注册多个Gemini API Key
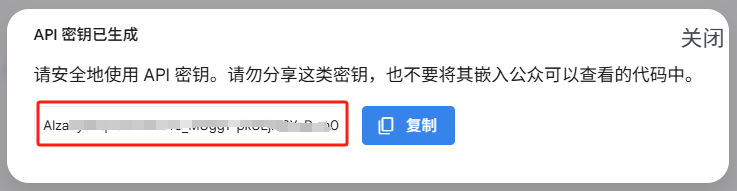
注册google账号就可以免费申请Gemini API密钥。
申请地址 https://aistudio.google.com/
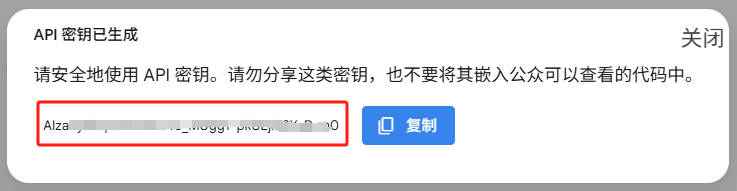
有了Gemini API密钥后就可以调用API使用Gemini 大模型的能力了。
注册多个google账号就可以申请多个Gemini API 密钥。
二、注册ClawCloud账号
ClawCloud是一个成立于2024年的云计算平台,总部位于新加坡,ClawCloud旨在简化技术栈的复杂性,帮助用户从编码到生产的整个过程只需几次点击即可完成 。它提供免费的每月5美元GitHub验证赠金,无需信用卡即可开始使用,并承诺在1分钟内完成设置 。
ClawCloud 在国内可以直接访问,Github 账户注册时间超过 180天就有每个月5美元的赠送额度,足够支撑我们部署gemini-balance的应用了。
点击 Github 登录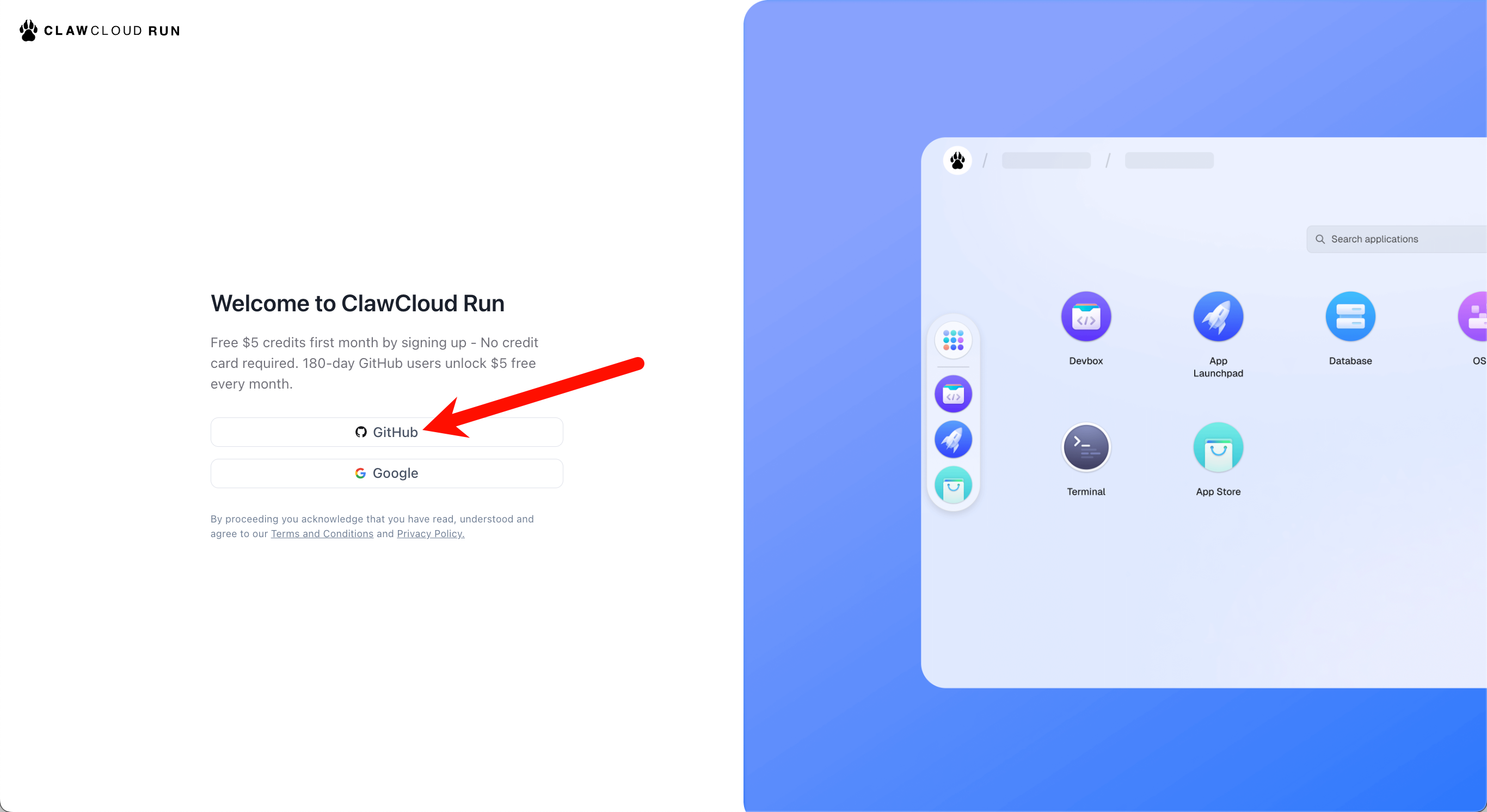
进入 Github 登录界面后,输入账户名、密码,随后点击 Sign in。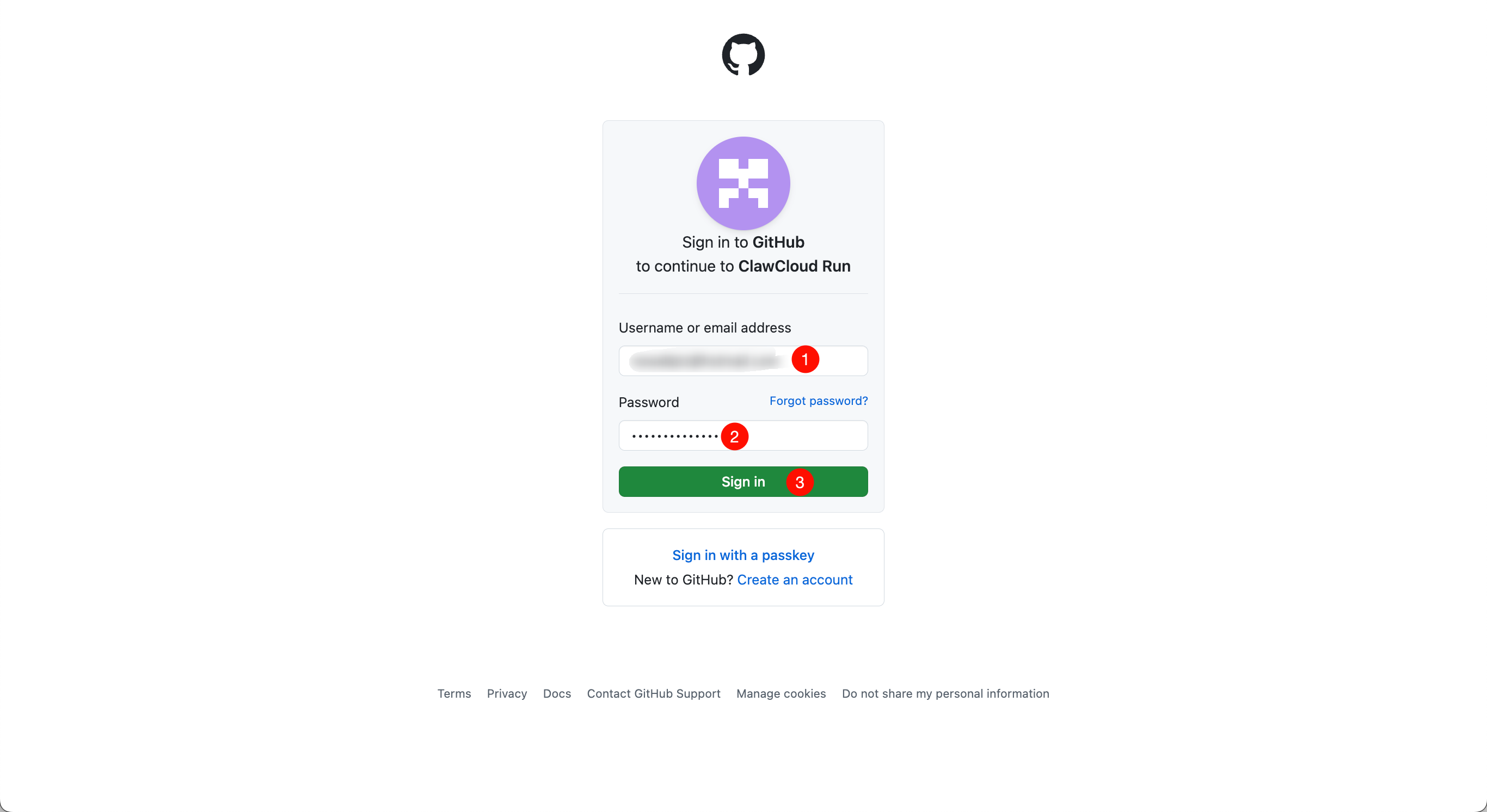
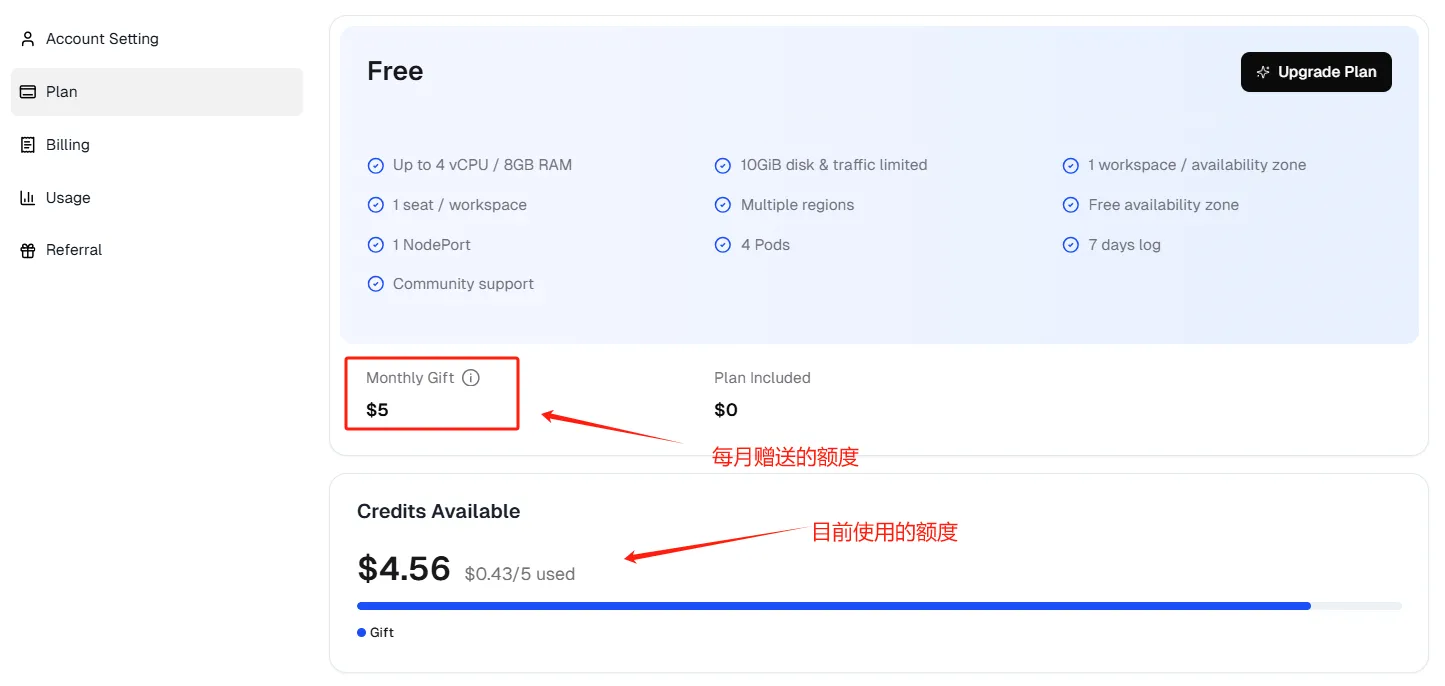
登录以后就在用户中心Account Center就可以看到每个月赠送的额度,如果有使用还可以看到目前使用的额度。
三、通过 ClawCloud Run 部署gemini-balance
gemini-balance官方有详细的部署文档
https://gb-docs.snaily.top/guide/setup-clawcloud-sqlite.html
大家可以按照这个文档一步步部署
- 部署项目
- 进入主界面后,点击左上角 Region,选择服务器地址。推荐选择 Singapore。选择完成后,网页会刷新,并在服务器地址前☑️。
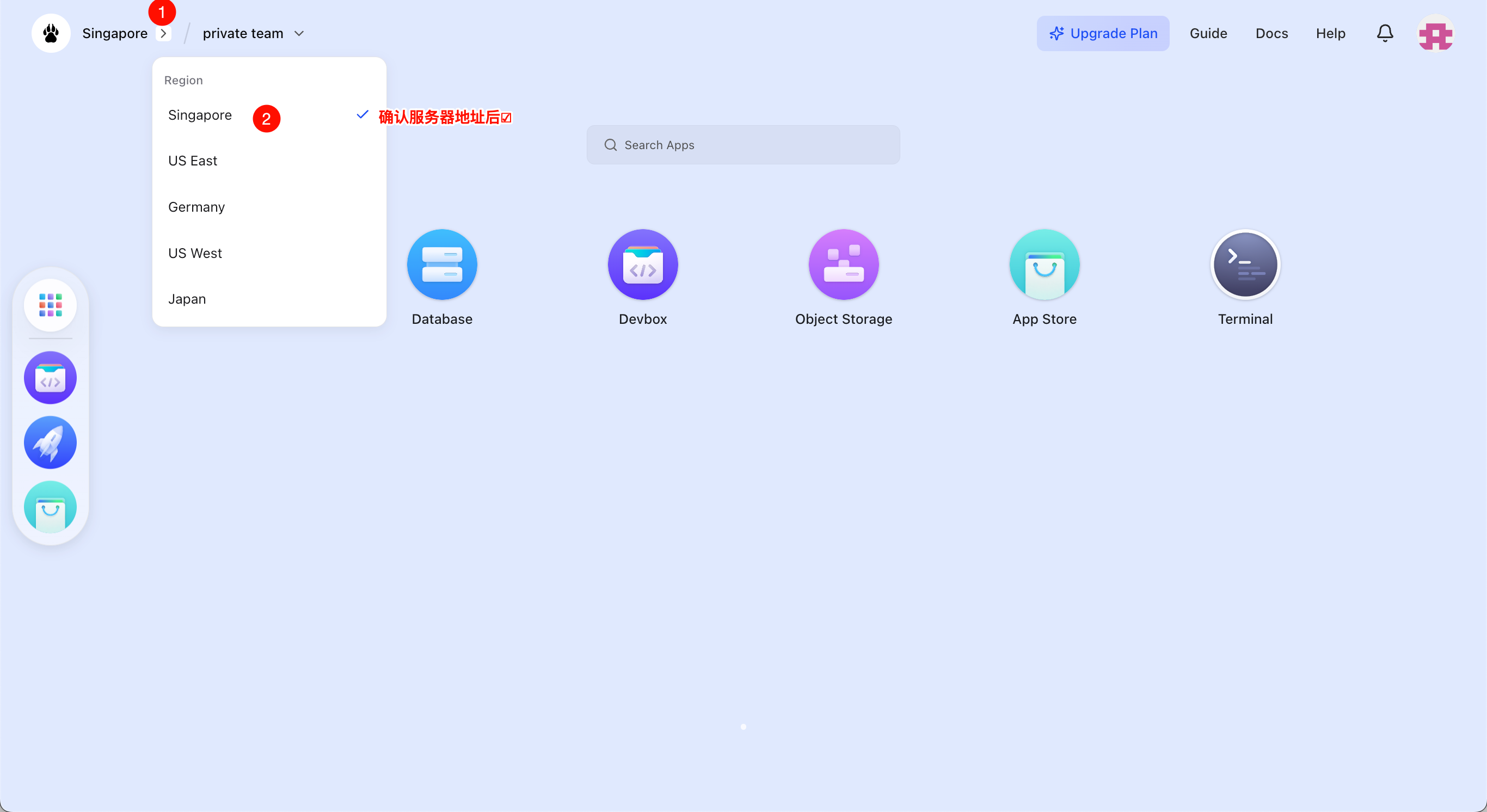
- 点击 App Launchpad。
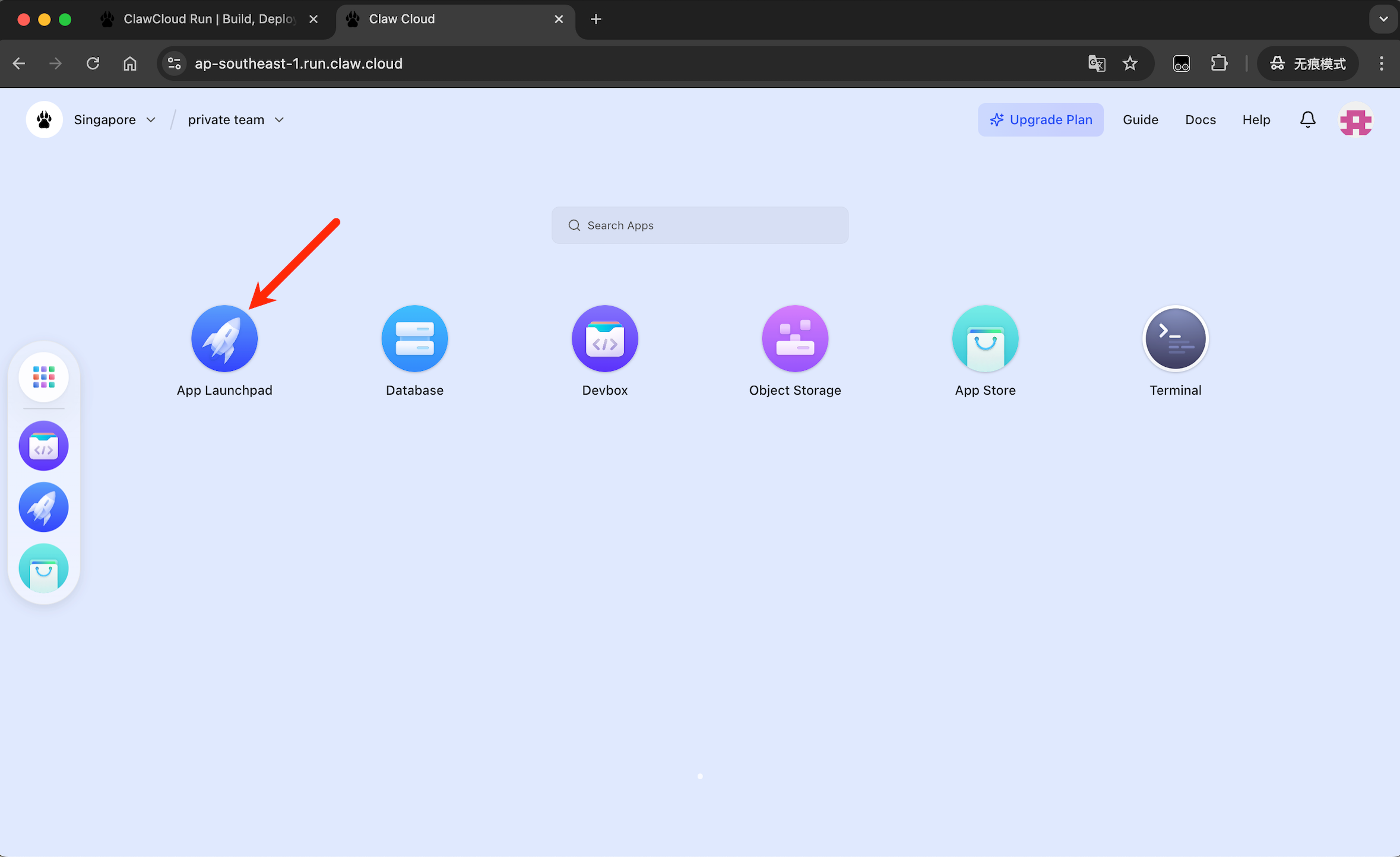
- 进入页面后,点击页面右上角 Create App,进入配置页面。
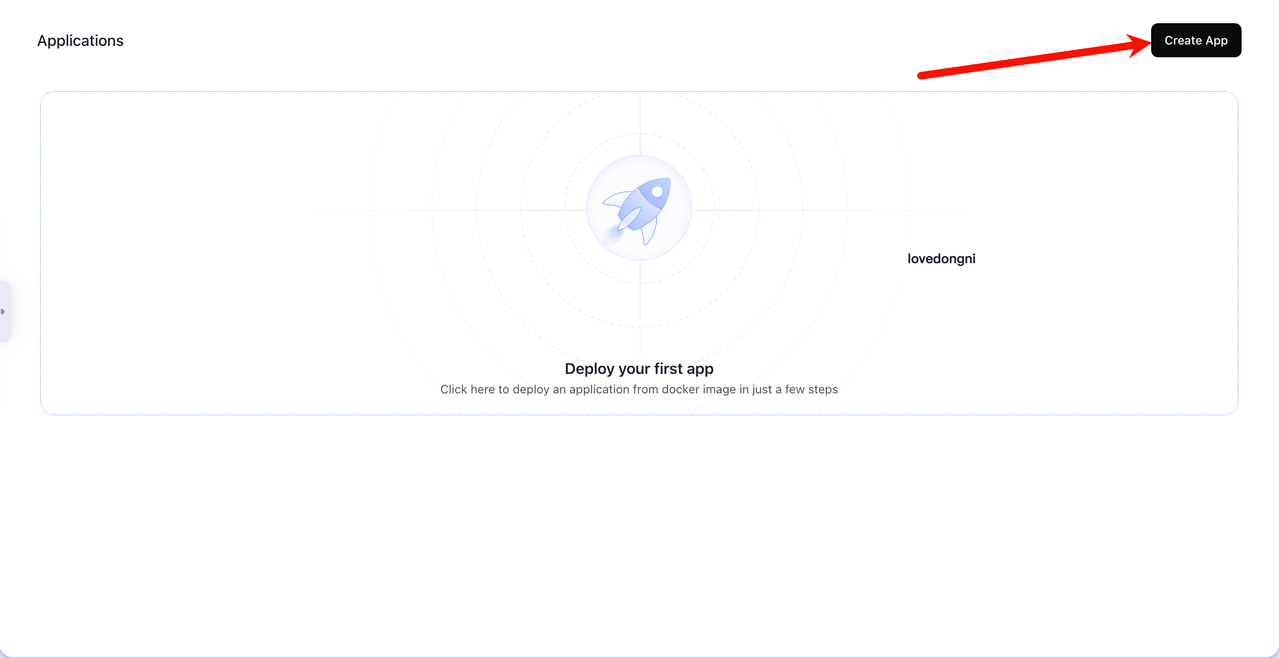
- 进入配置页面后,按顺序填写信息(不熟悉项目名称的,请打开在线翻译)。
- Application Name:为方便识别管理,建议填写本项目名字
geminibalance - Image:
Public- Image Name:
ghcr.io/snailyp/gemini-balance:latest
- Image Name:
- Application Name:为方便识别管理,建议填写本项目名字
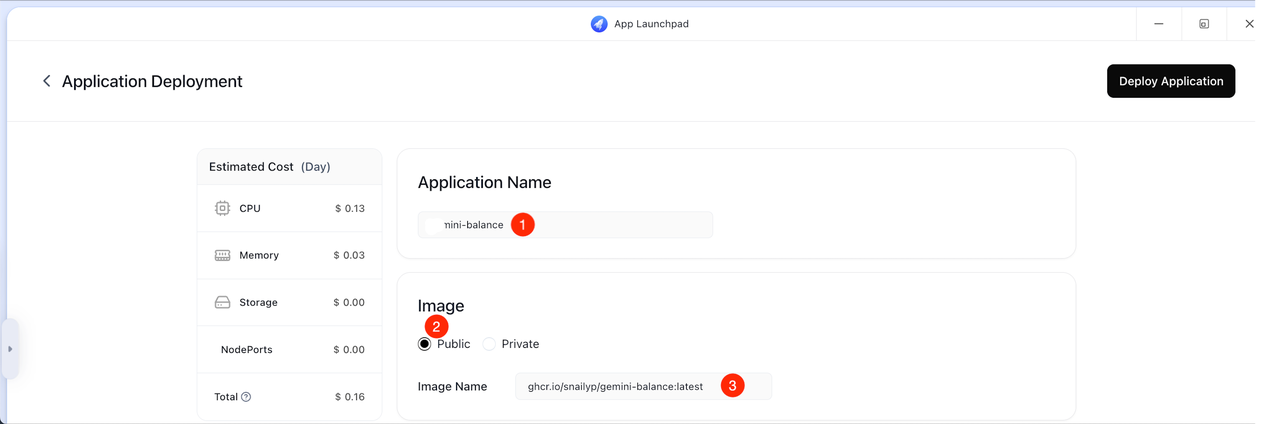
- Usage:`Fixed`;
- Replicas:`1`
- CPU:`1`
- Memory:`512`
> 说明:1. 若登录账号只选择部署 1 个项目,则推荐上述最高免费配置。2.目前免费用户每月流量为 10g,超出部分 0.05 美元/g。可根据流量使用情况选择服务器配置。 
- Network
- Container Port:`8000`
- Enable Internet:点选为`Access`状态
- Advanced Configura
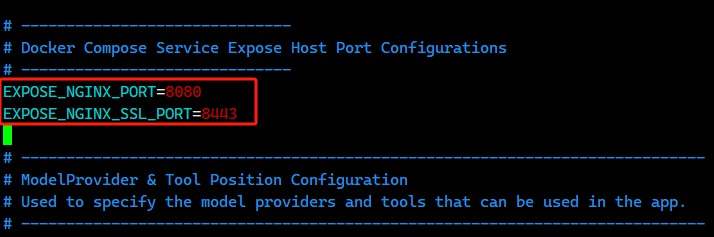
- Environment Variables:点击 Add,随后粘贴以下变量。填写完成后点击 Add 完成配置。
1
2
3
4
5
DATABASE_TYPE=sqlite
SQLITE_DATABASE=default_db
API_KEYS=[""]
ALLOWED_TOKENS=[""]
AUTH_TOKEN=TZ=Asia/Shanghai
变量说明如下:
| 变量名 | 说明 | 格式及示例 |
|---|---|---|
| API_KEYS | Gemini API 密钥列表,用于负载均衡 | [“your-gemini-api-key-1”,”your-gemini-api-key-2”] |
| ALLOWED_TOKENS | 允许访问的 Token 列表 | [“your-access-token-1”,”your-access-token-2”] |
| AUTH_TOKEN | 【可选】超级管理员token,具有所有权限,不填默认使用 ALLOWED_TOKENS 的第一个 | sk-123456 |
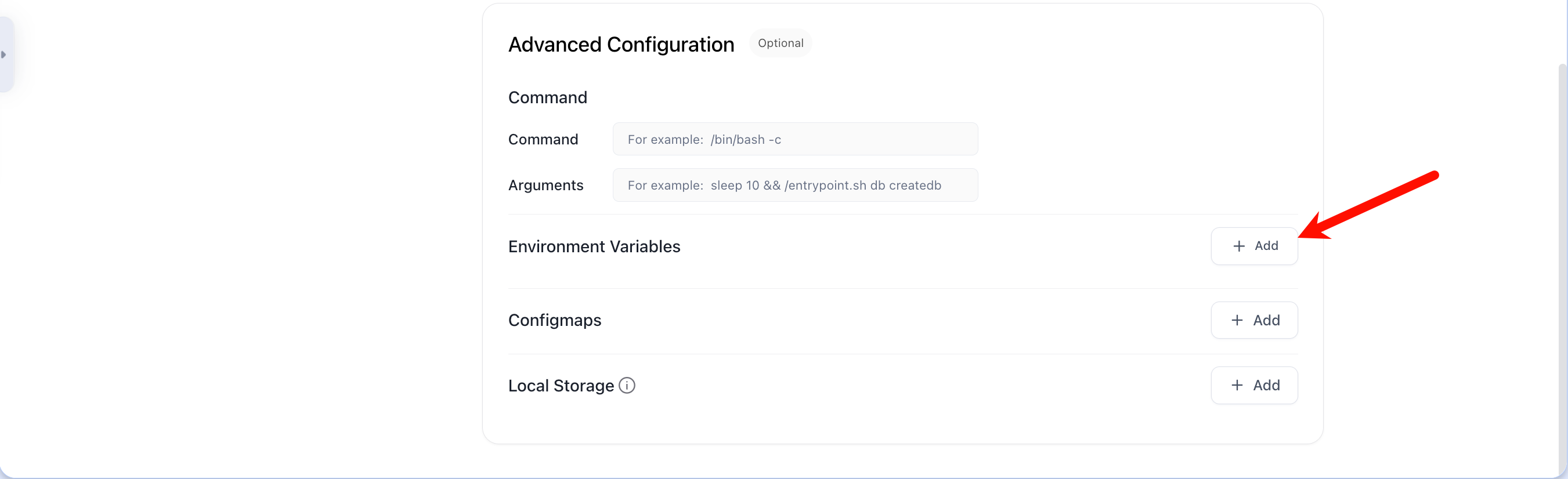
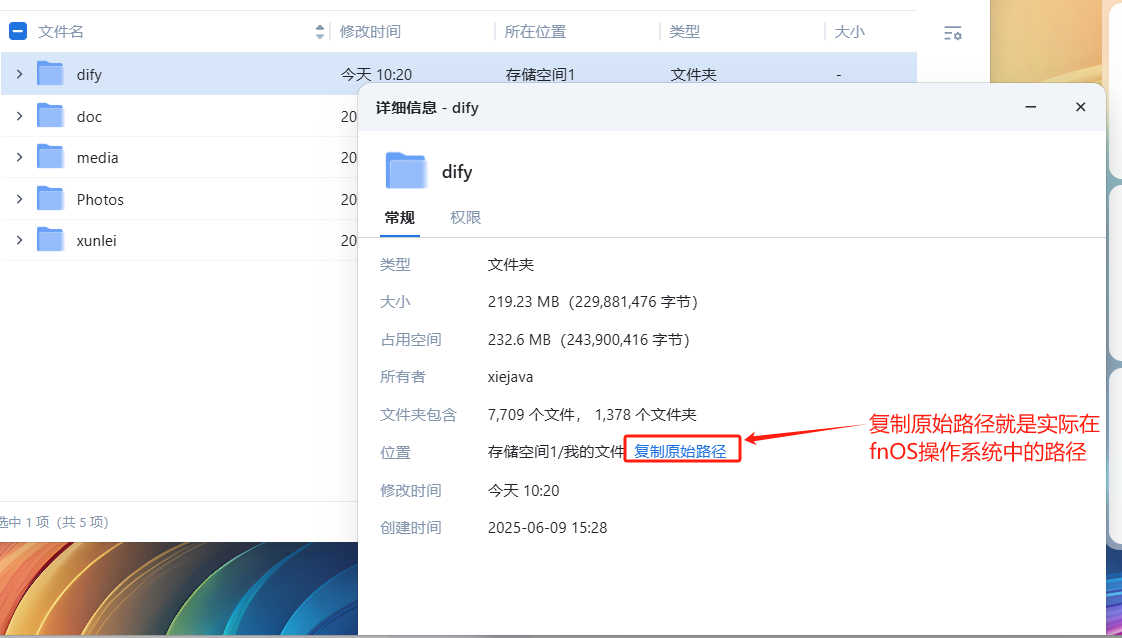
- 添加完环境变量后,再按照下图设置storage
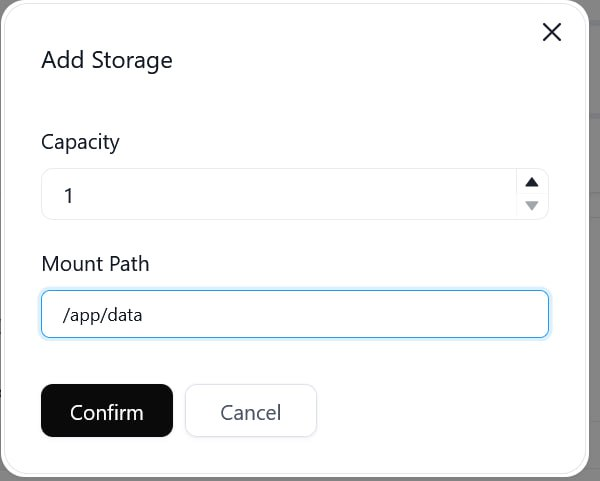
- 返回页面最上方,点击 Deploy Application。弹窗提示Are you sure you want to deploy the application?选择 Yes。
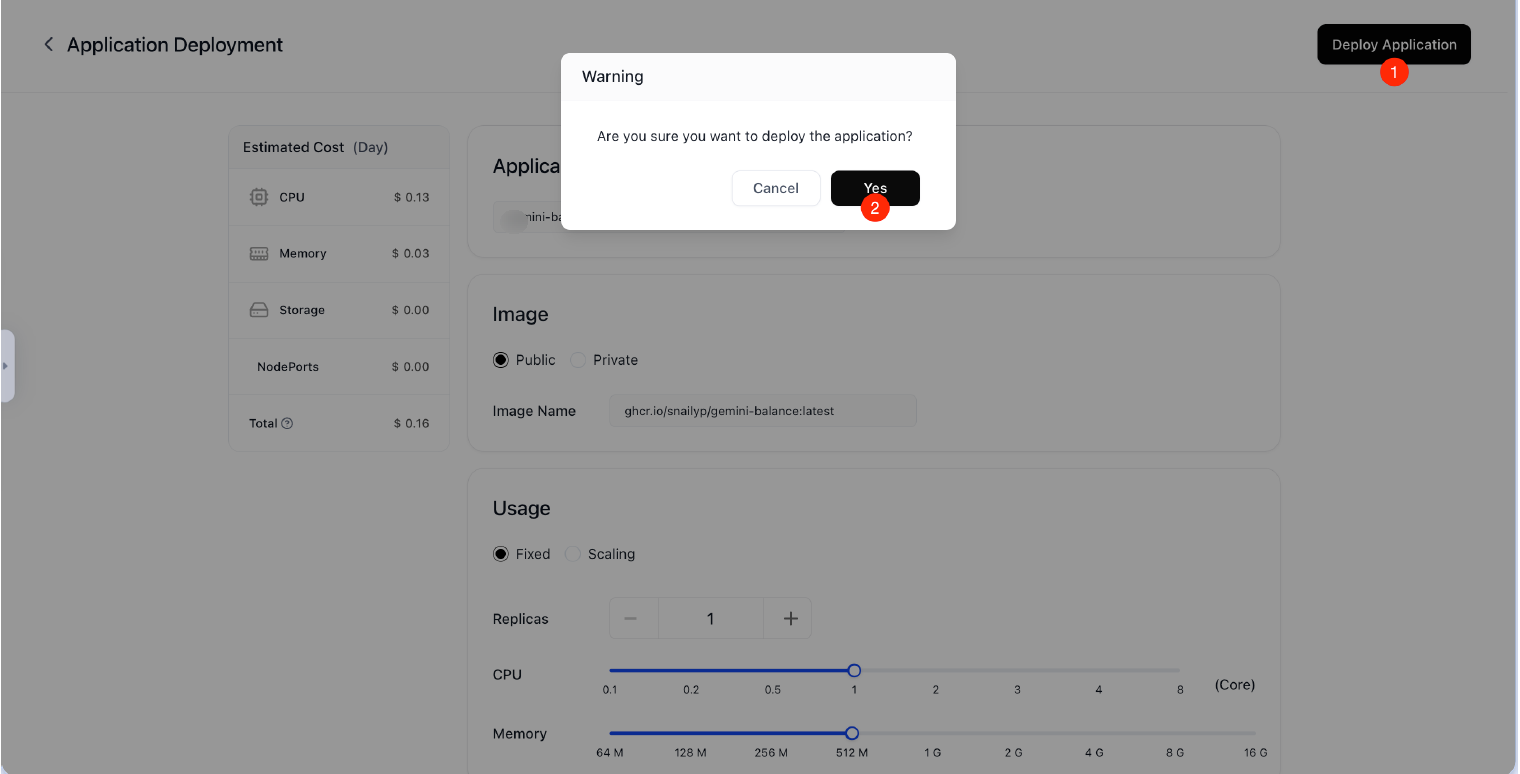
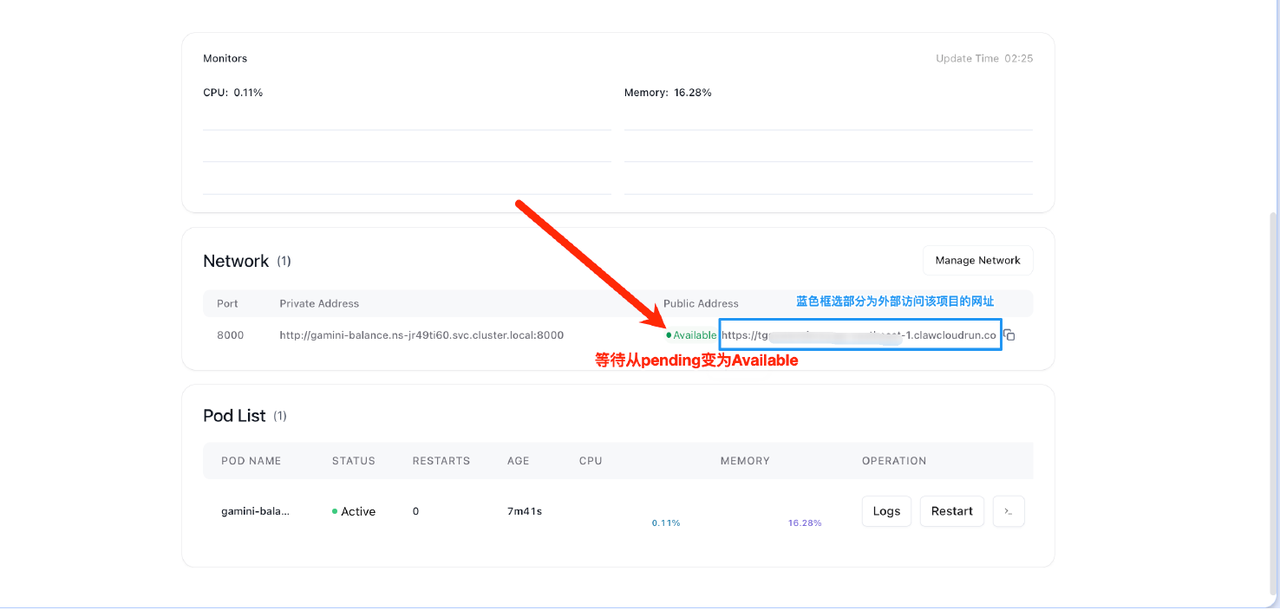
- 等待几秒后,跳转至状态界面。此时,请确认页面左上角显示 running。若显示为其他状态,请稍后片刻;仍未显示 running,请确认你配置选项是否正确。需要修改的,可点击页面右下角 Manage Network 选项修改参数,或删除该项目重新部署。
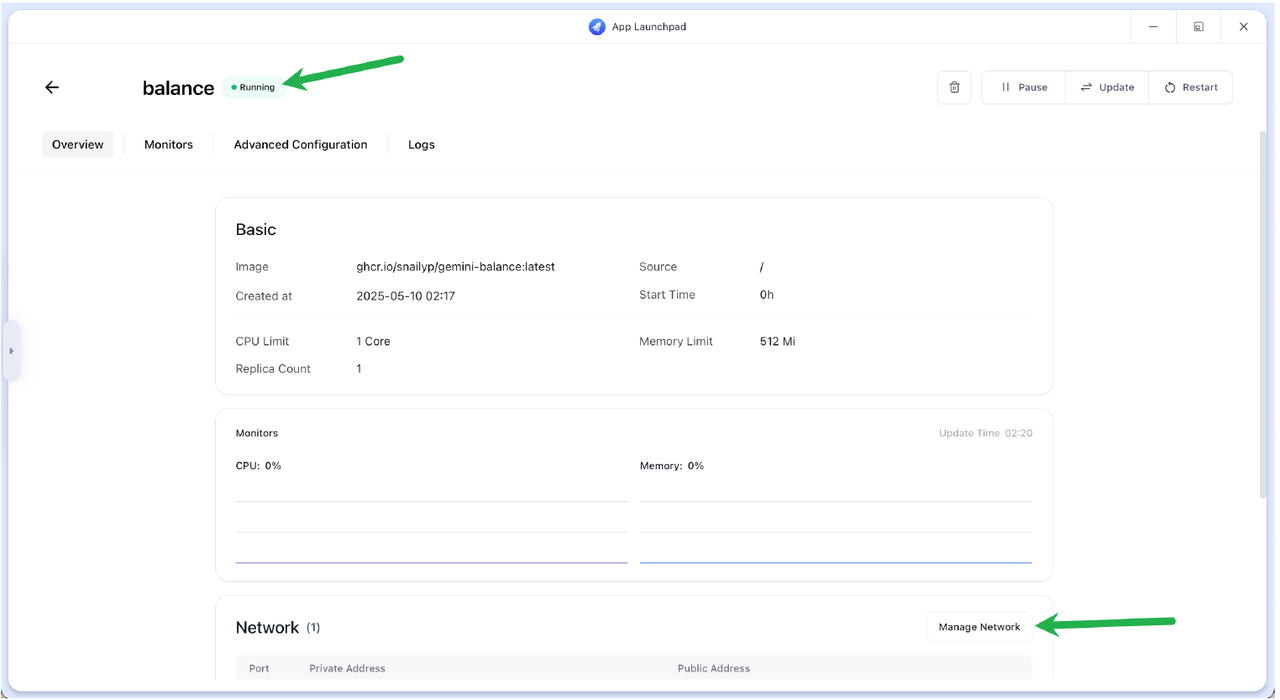
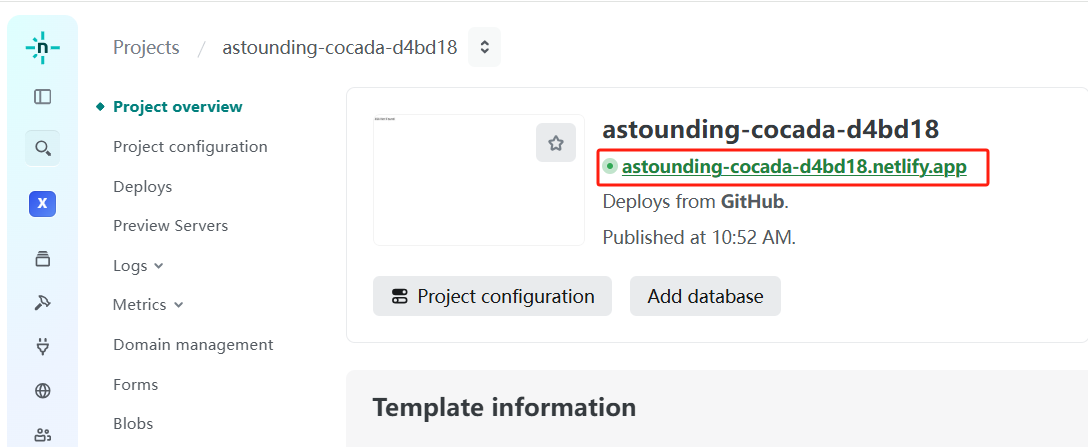
- 将页面滚动到最下方,在 Network 选项卡中,查看右侧公网地址配置情况。一般情况下,显示 pending 表明还在处理当中,需要等待 2~5 分钟,直至pending 状态变为Available。 实际情况下, 2 分钟后即使公网地址前显示pending,亦可尝试在新的浏览器标签中打开该地址。若网页能正常显示本项目登录界面,则正常使用即可。若公网地址前的pending状态超过 10 分钟,且无法打开登录界面,原因可能是服务器过载,需要更长等待时间。建议换区或换服务商重新部署。
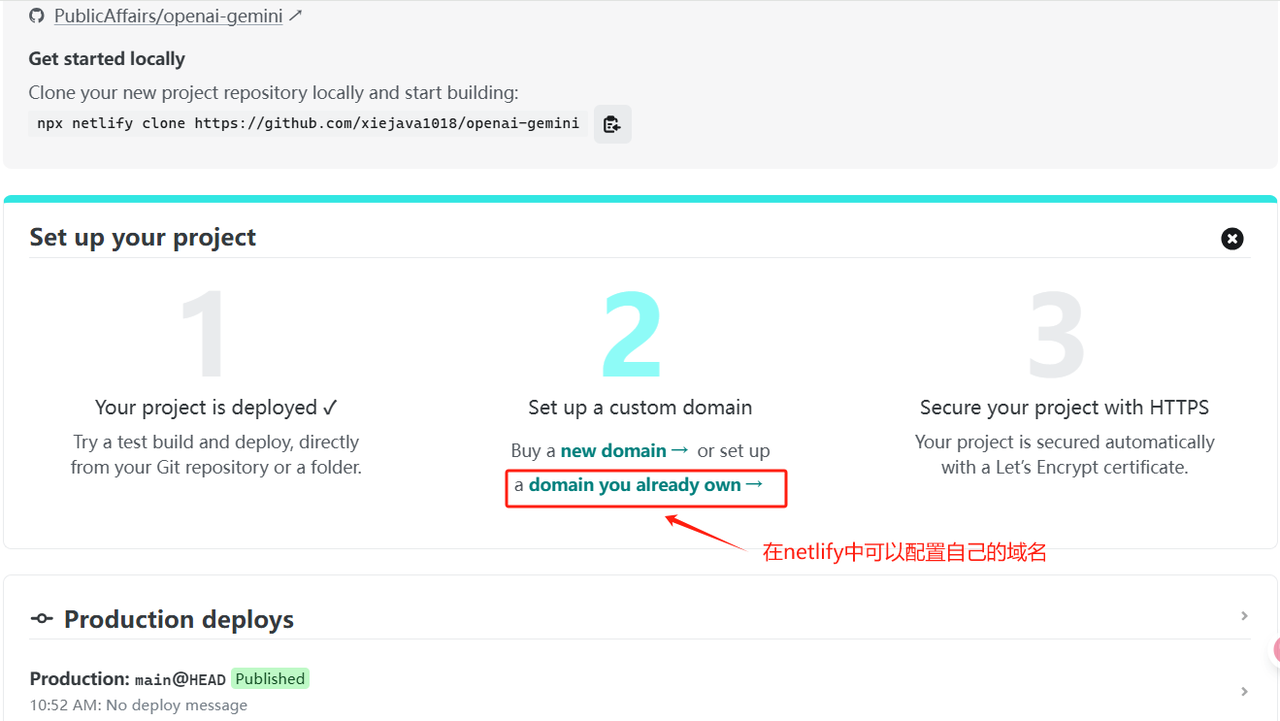
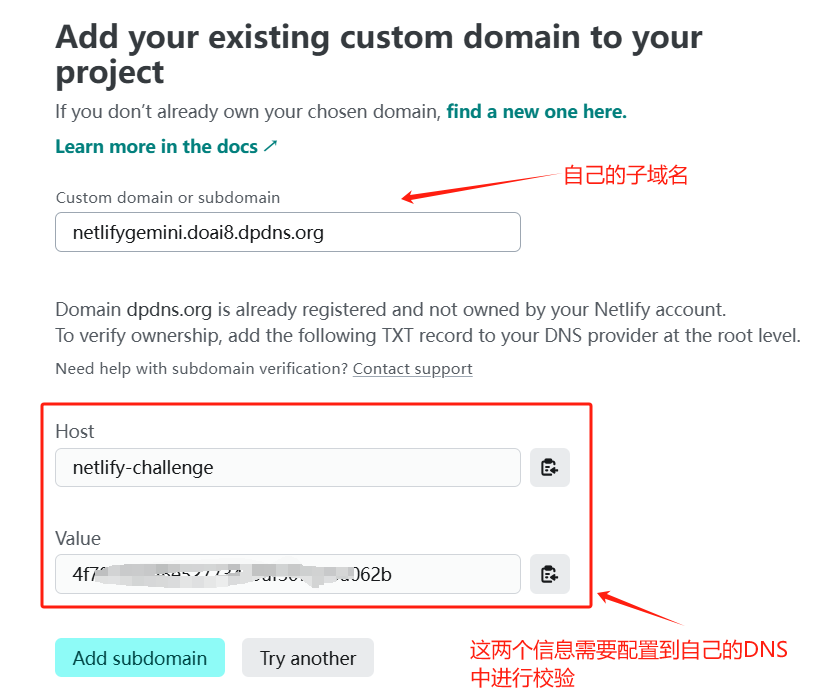
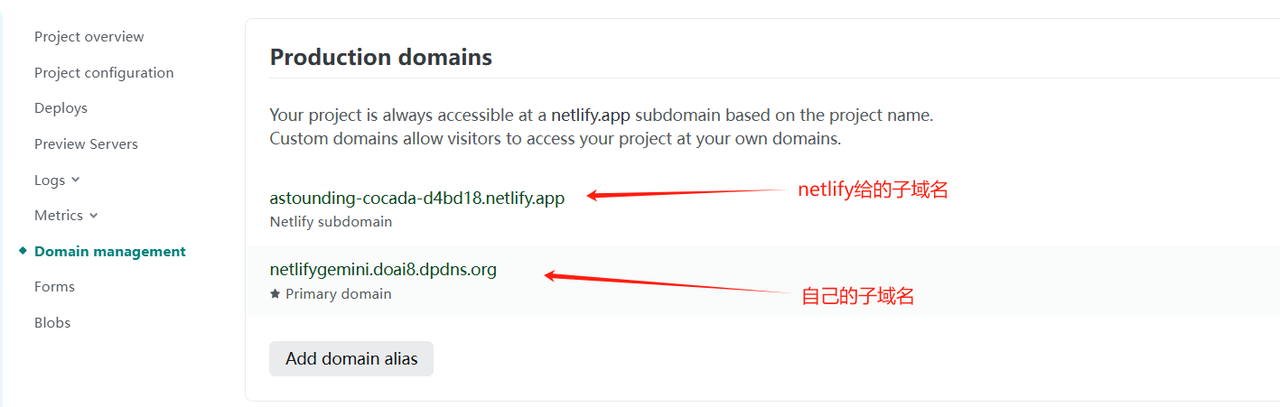
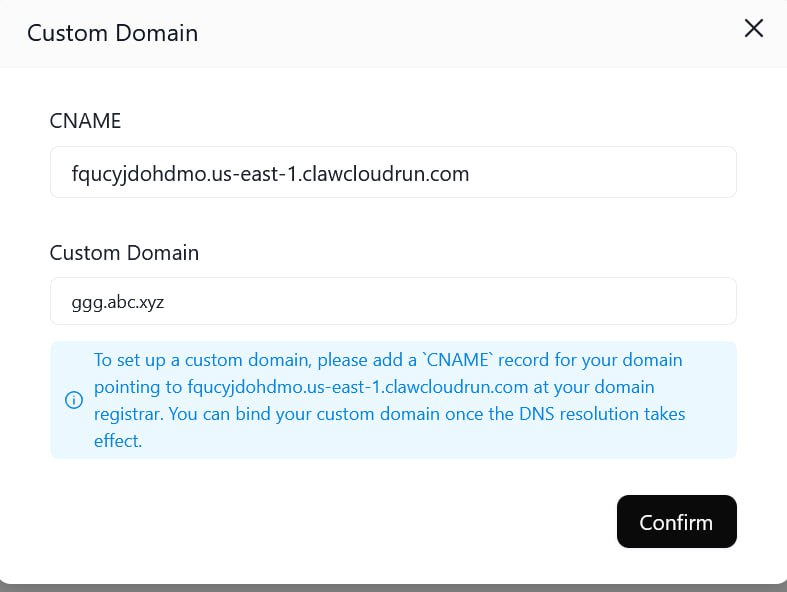
- 设置自定义域名
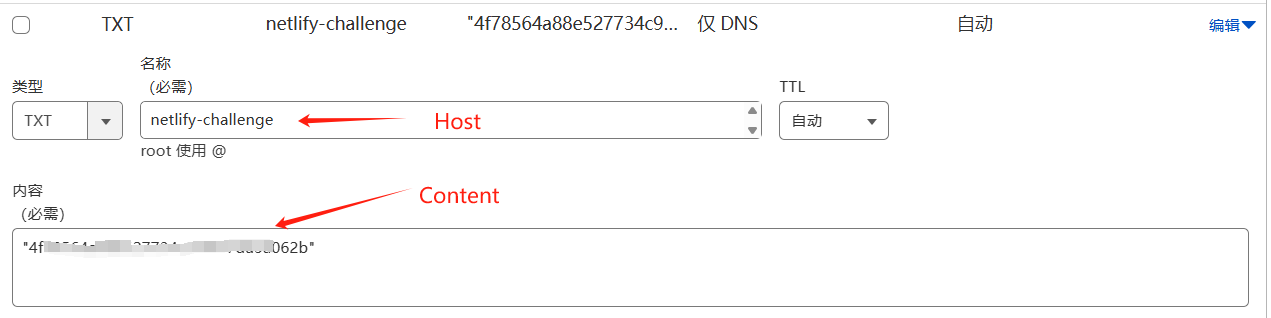
- 在cloudflare添加cname记录,如我希望域名为ggg.abc.xyz,cloudflare中这样设置,abc.xyz为托管在cloudflare域名
- 在clawcloud这样设置,这样就可以自定义域名访问
四、使用gemini-balance监控配置页面
gemini-balance贴心的带了一个监控配置页面,在这个界面可以配置多个Gemimi API 也可以监控Gemini API的调用情况。
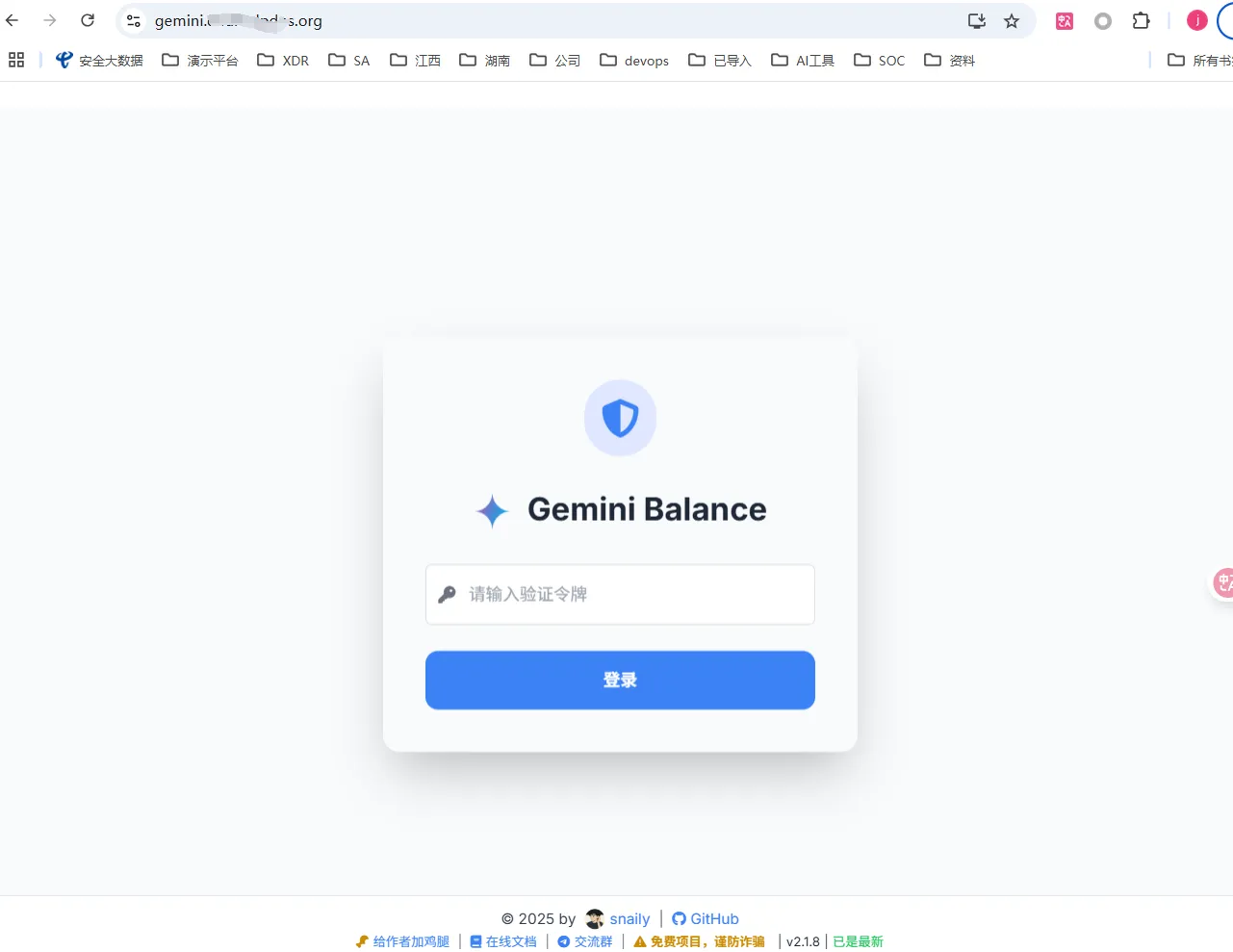
- gemini-balance监控页面配置
- 复制项目公网访问地址后,在浏览器中打开。随后进入登录界面,输入密码即可进入。(如果没有更改配置,密码是
your-access-token-1)
- 复制项目公网访问地址后,在浏览器中打开。随后进入登录界面,输入密码即可进入。(如果没有更改配置,密码是
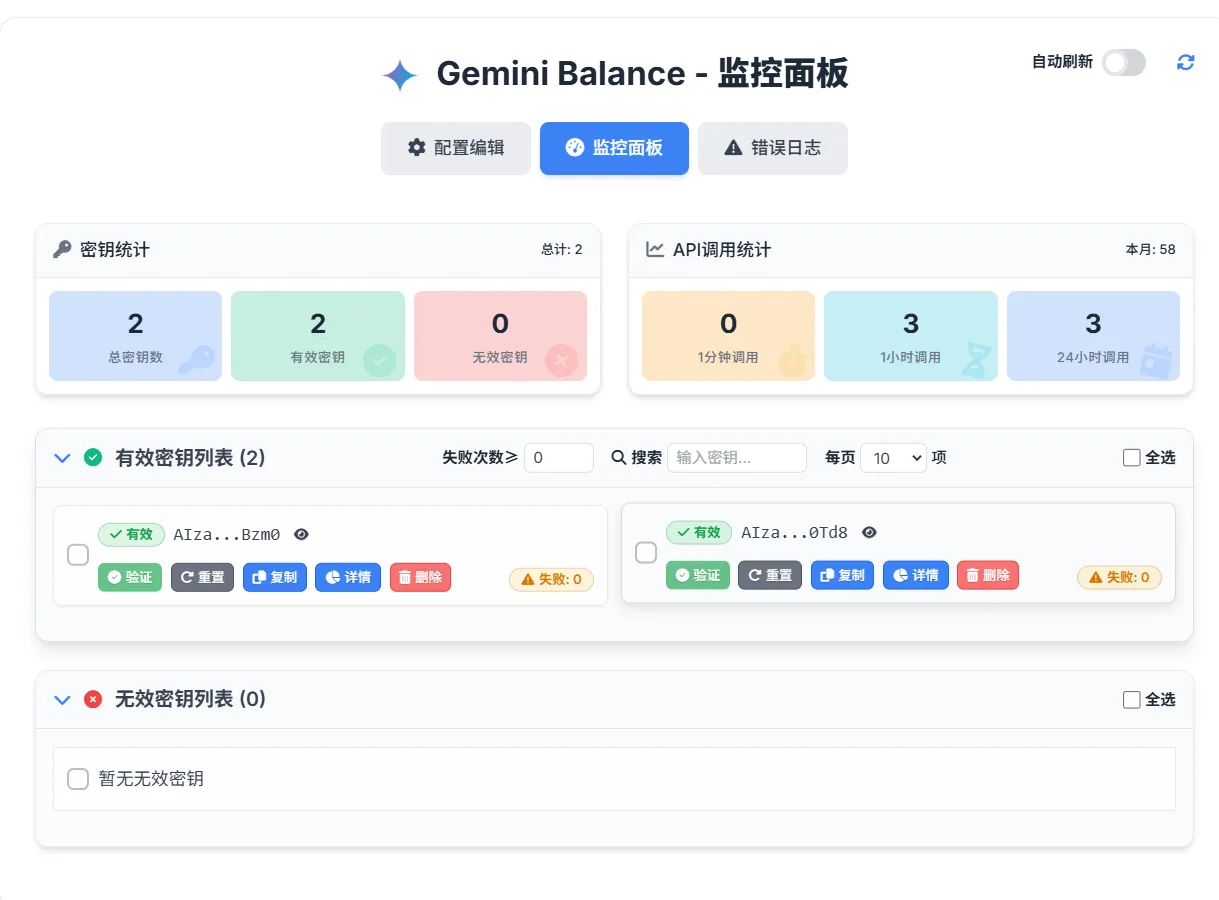
登录后可以进行相应的配置如添加更多的Gemini API Key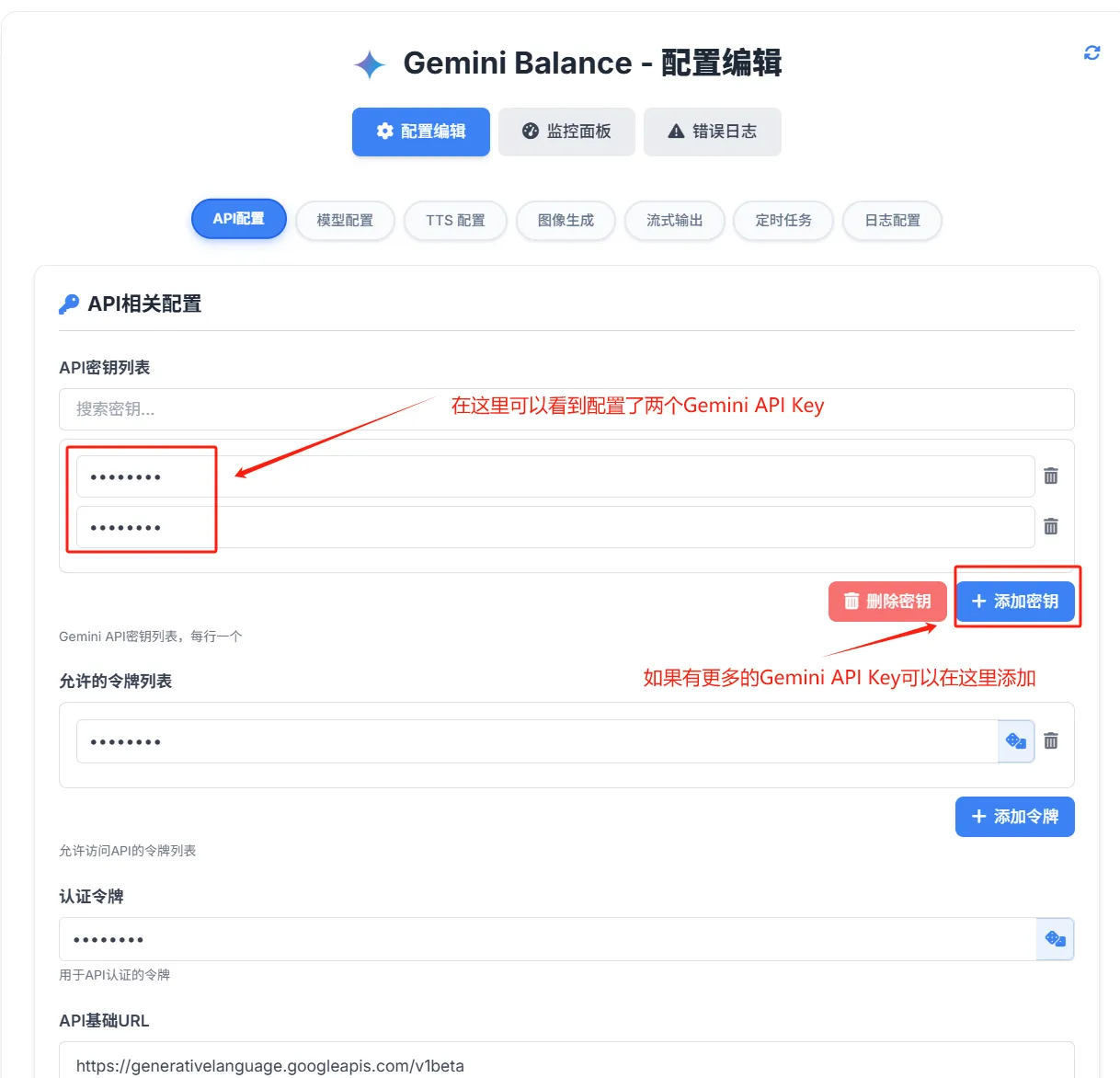
也可以监控Gemini API Key的调用情况
五、在 cherry studio使用GeminiBalance
以 cherry studio 为例
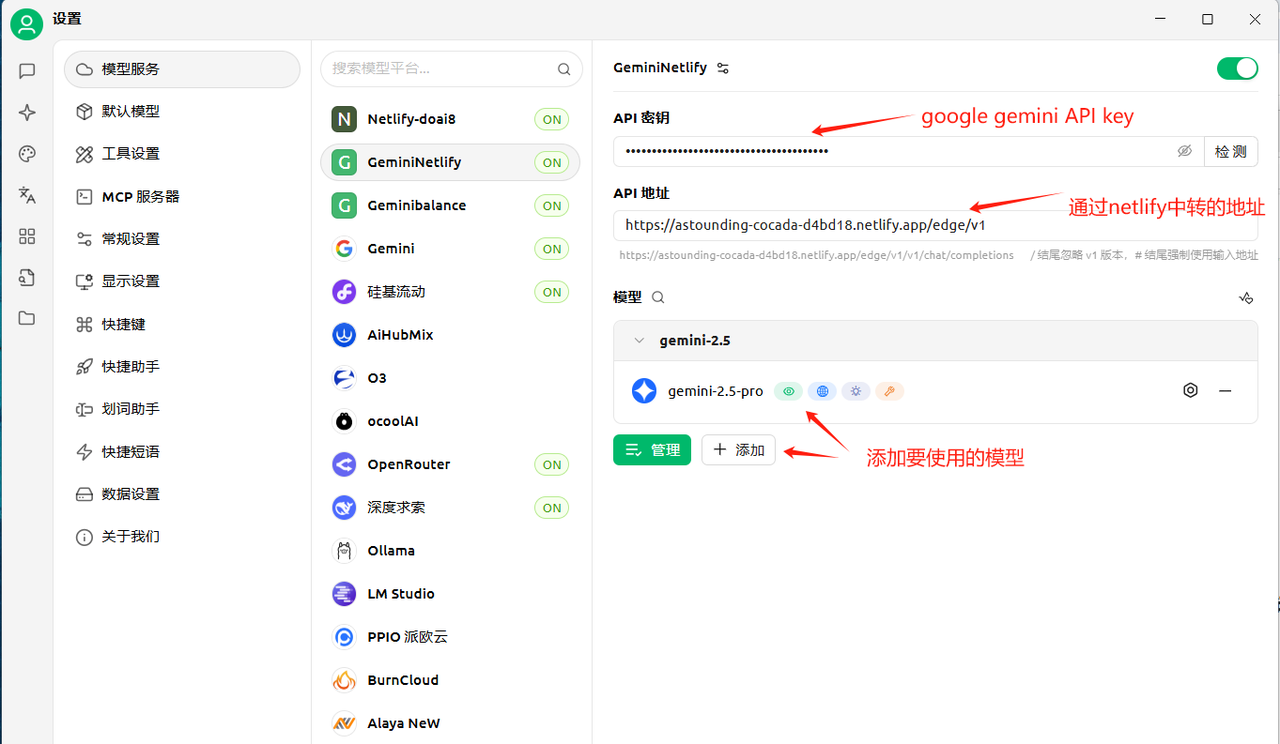
1. 添加提供商。
- 提供商名称:任意填写
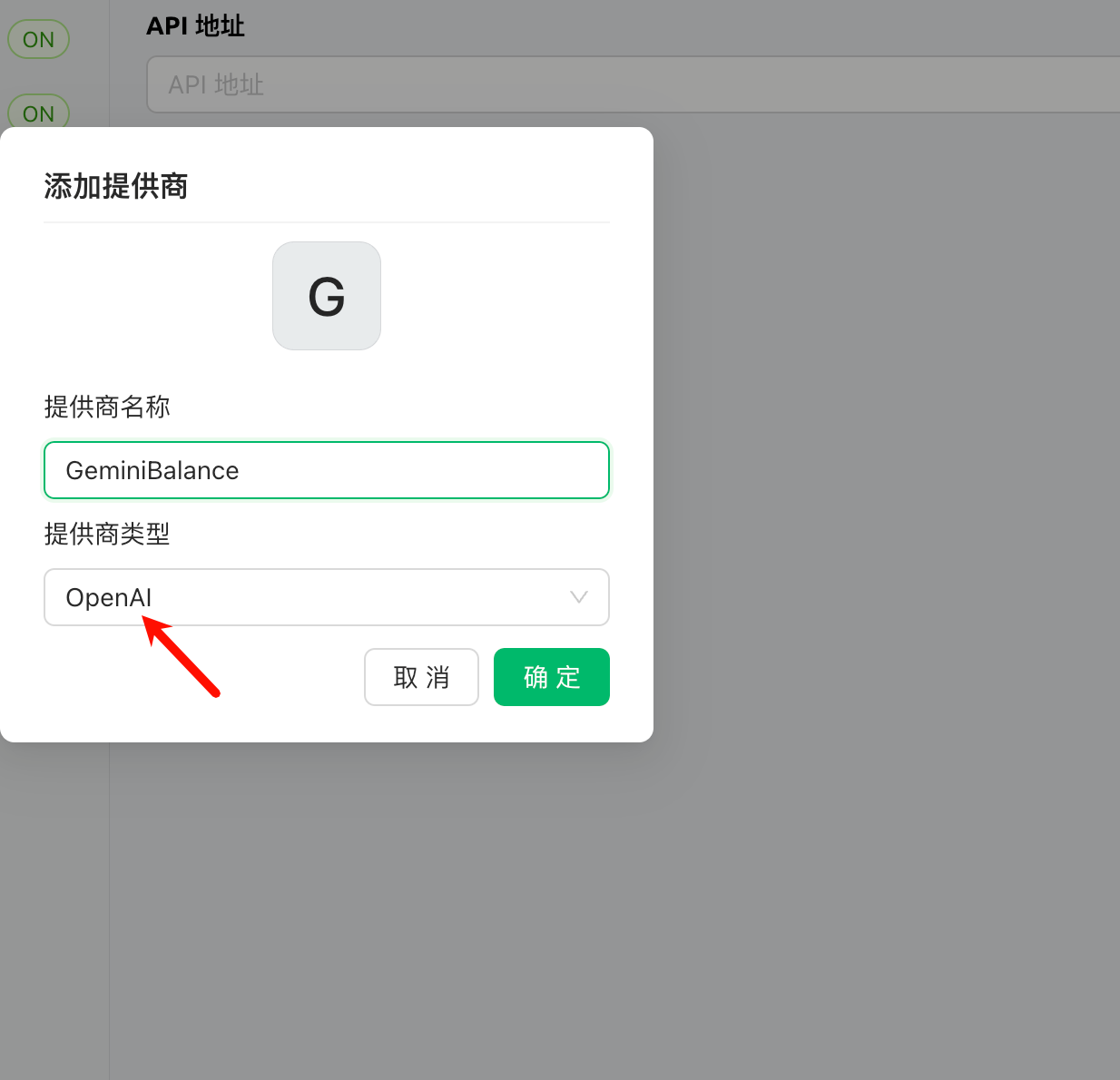
2. 配置
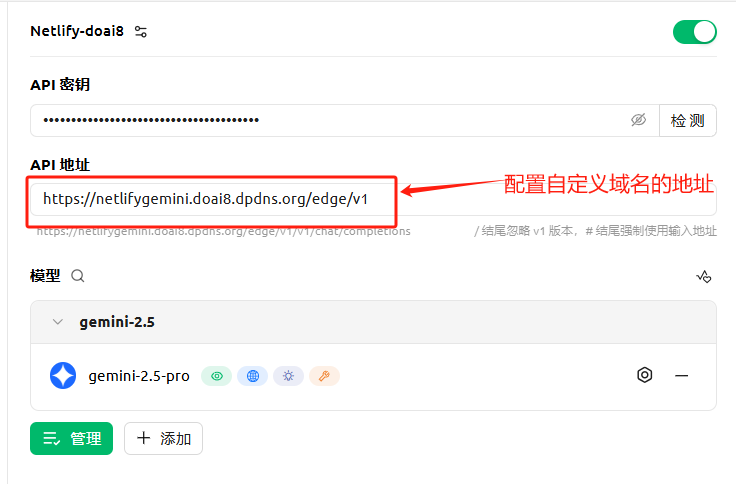
- API 密钥:填写监控面板“API 密钥”选项卡中的“允许的令牌列表”。
- API 地址:填写 ClawCloud 中的公网访问地址。注意结尾不要出现“/”。 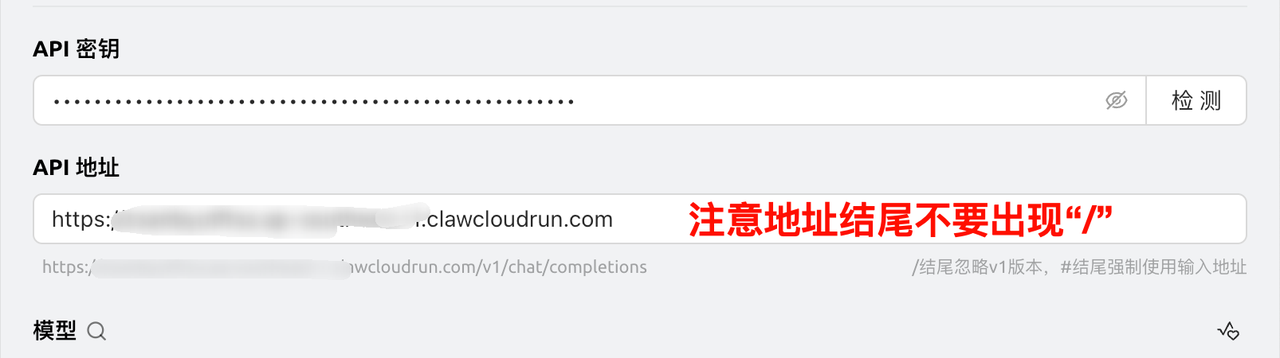
3. 添加模型
4. 点击“管理”,添加模型。 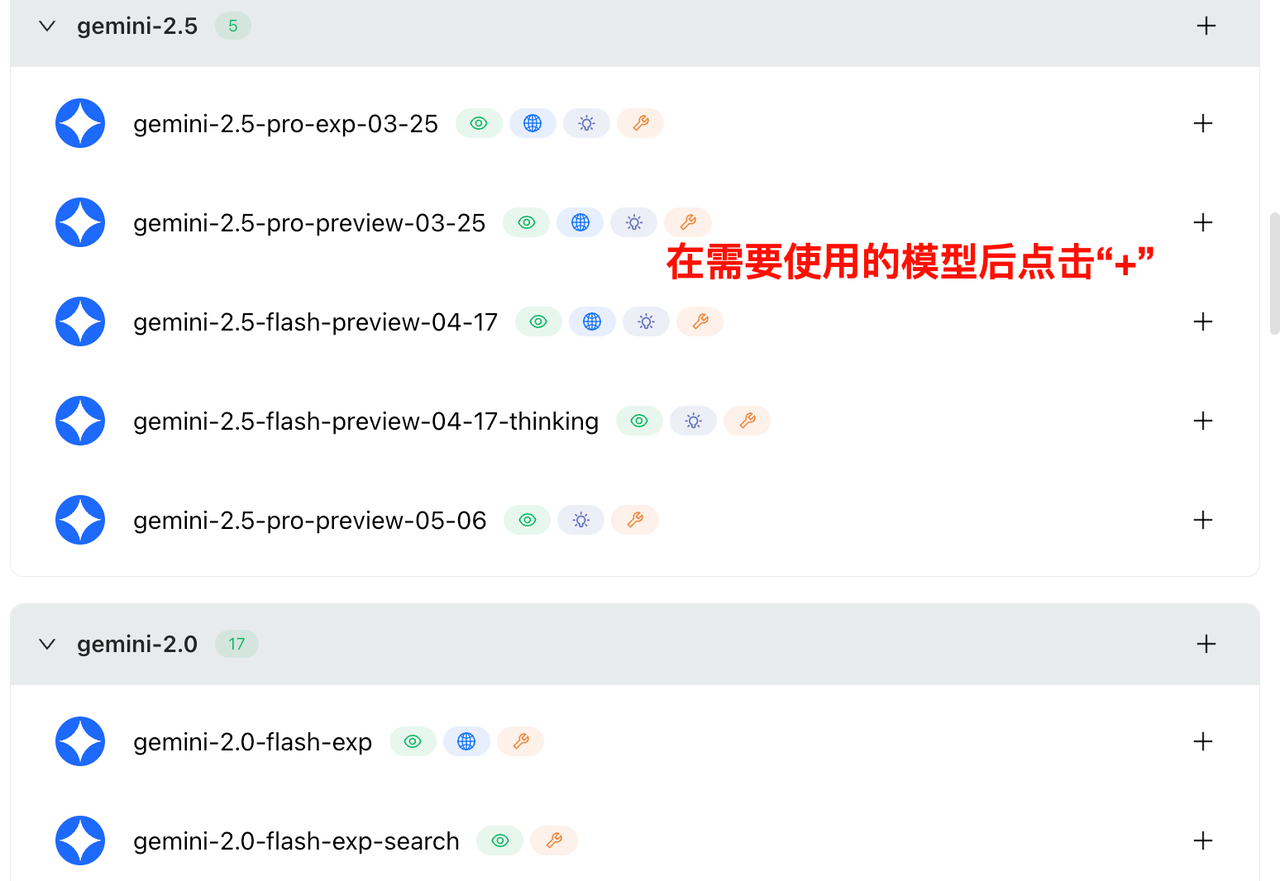
至此,部署完成。
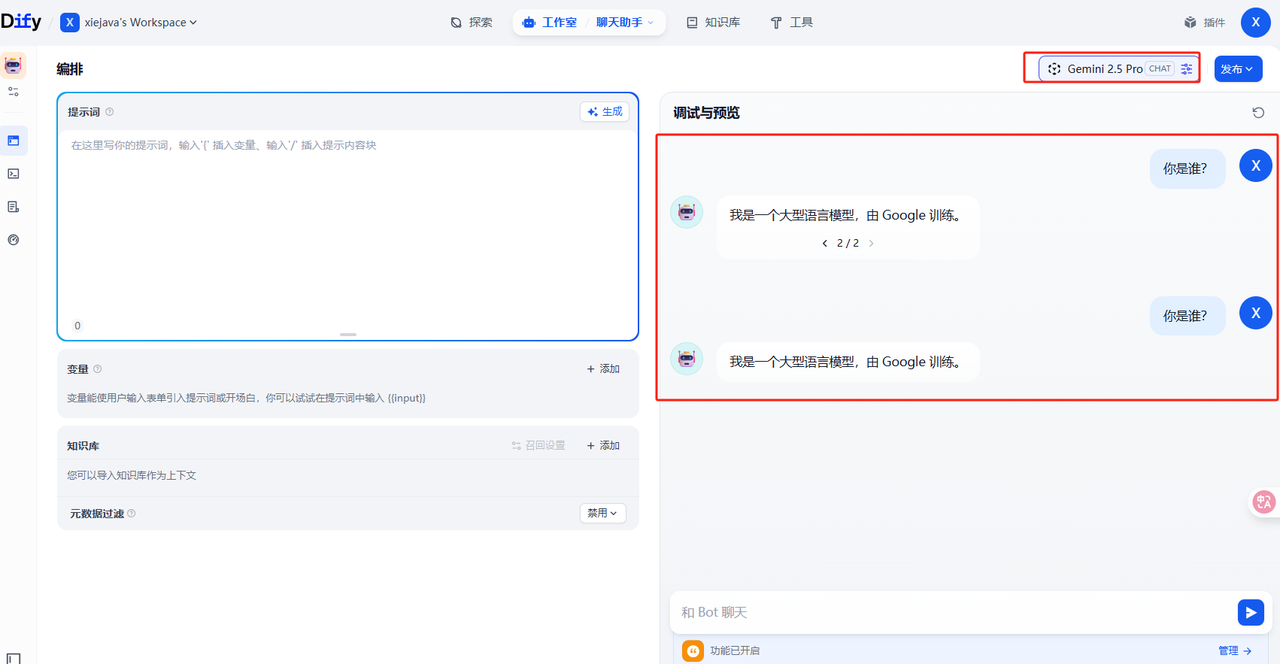
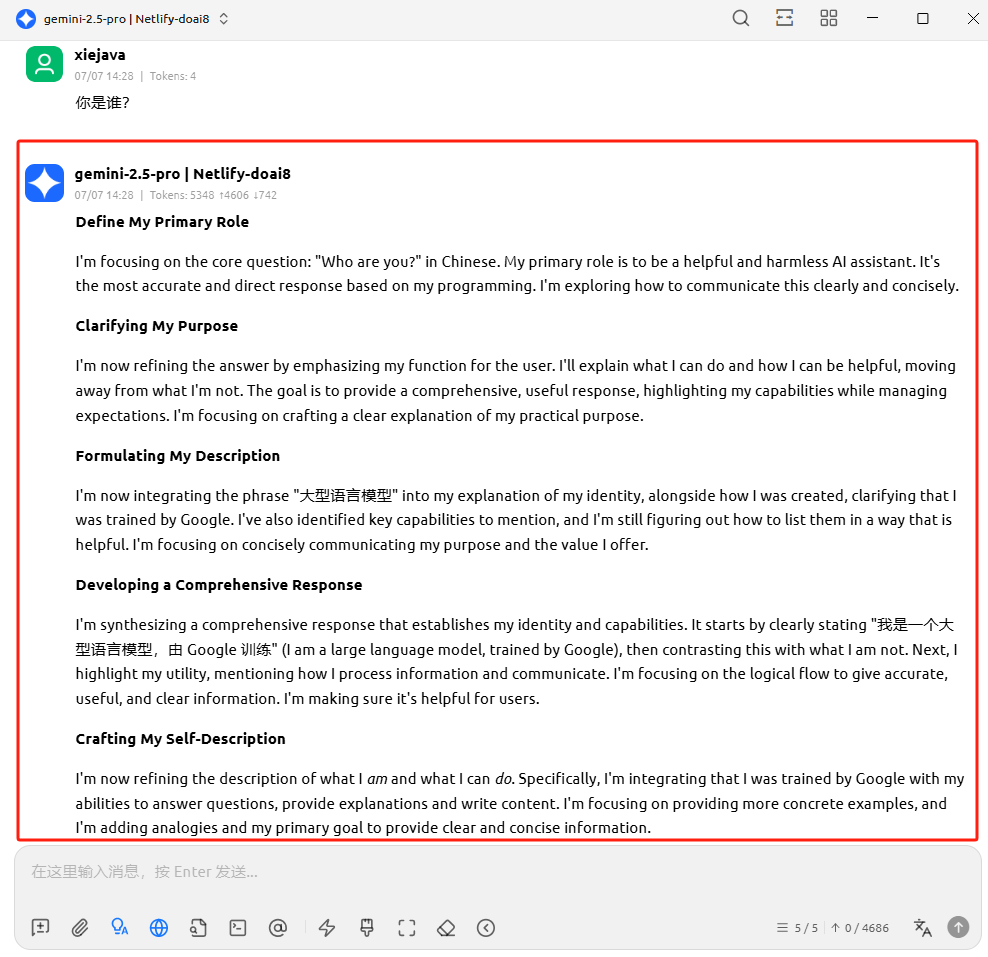
最后看调用效果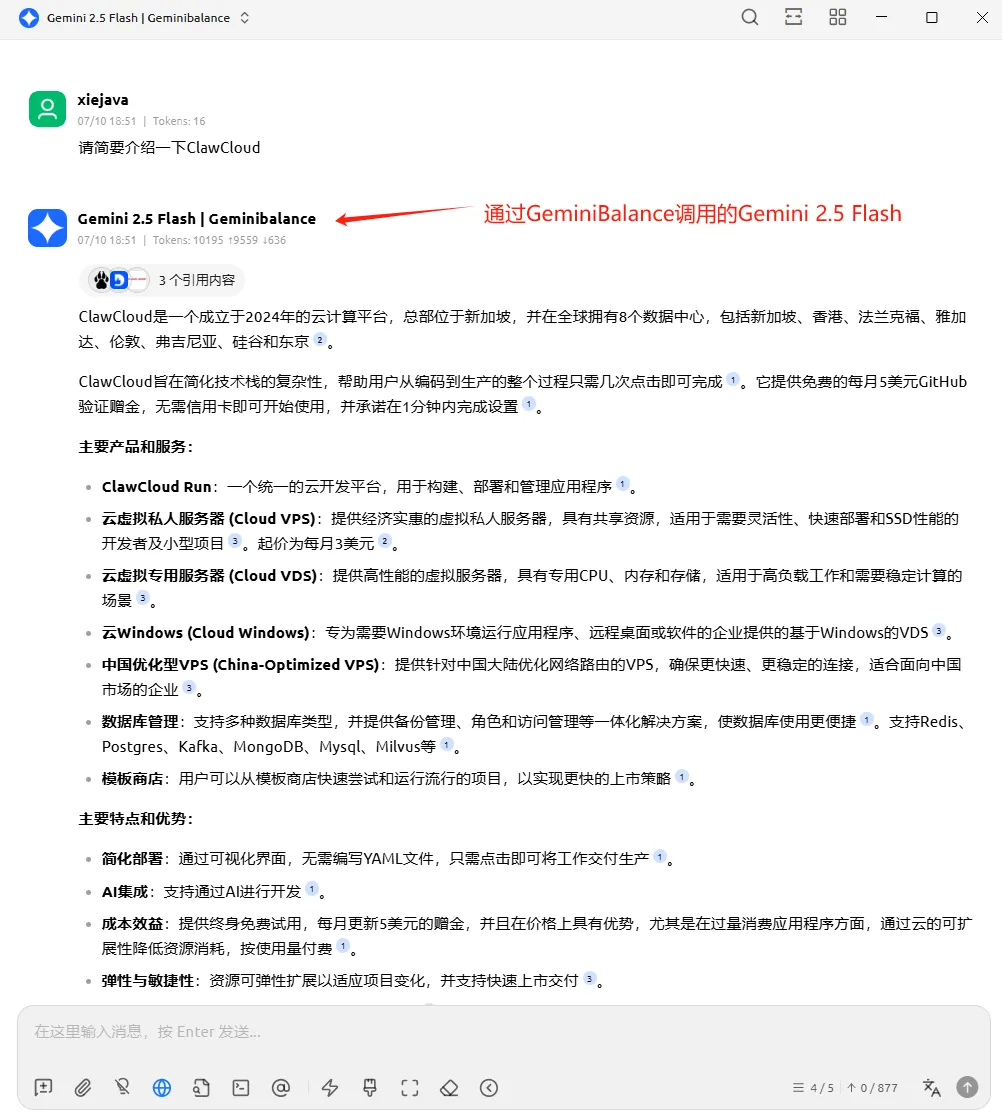
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!