数据分析离不开数据运算,在介绍完pandas的数据加载、排序和排名、数据清洗之后,本文通过实例来介绍pandas的常用数据运算,包括逻辑运算、算术运算、统计运算及自定义运算。
一、逻辑运算
逻辑运算是程序代码中经常用到的一种运算。pandas的逻辑运算与Python基础语法中的逻辑运算存在一些差异。pandas的逻辑运算主要用于条件过滤根据条件逻辑运算得出的结果过滤检索出相应的数据。 我们来看一些例子: 数据集为学生数据集
| |
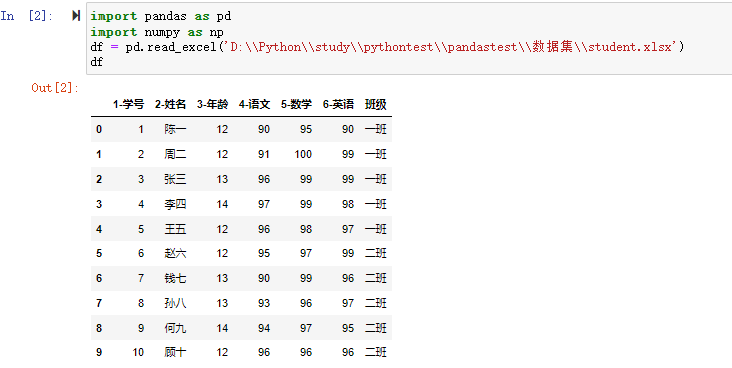 我们要过滤检索出语文成绩大于95分的数据,通过
我们要过滤检索出语文成绩大于95分的数据,通过df['4-语文']>95的条件语句,可以得到一个结果为bool值的Series,True表示满足语文成绩>95分的,False表示不满足语文成绩>95的。
在pandas中,将Series与数值进行比较,会得到一个与自身形状相同且全为布尔值的Series,每个位置的布尔值对应该位置的比较结果。
这种进行比较的代码,返回值是布尔值,是一种布尔表达式,也可以被称为逻辑语句,只要代码返回的结果是布尔值,都可以把代码当成逻辑语句。
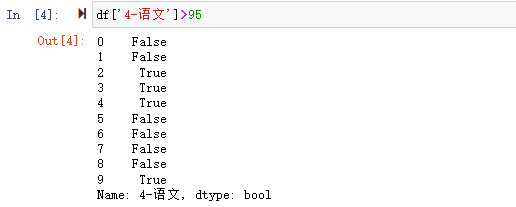 根据逻辑语句的布尔值,可以用来对数据进行筛选,按我们的需要从大量数据中过滤出目标数据。如我们要过滤出语文成绩大于95的数据,就可以用上述逻辑语句的布尔值进行筛选。
根据逻辑语句的布尔值,可以用来对数据进行筛选,按我们的需要从大量数据中过滤出目标数据。如我们要过滤出语文成绩大于95的数据,就可以用上述逻辑语句的布尔值进行筛选。
| |
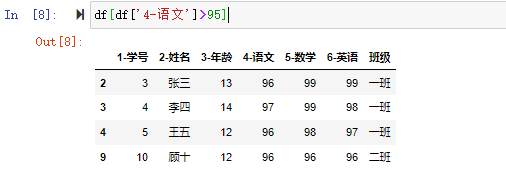
除了直接的比较,pandas中有很多函数都会返回布尔值,如all(),any(),isna()等对整个DataFrame或Series的判断结果,eq(),ne(),lt(),gt()等比较函数的结果,都是布尔值。 逻辑语句是为逻辑运算服务的,可以直接作为判断条件。在复杂的逻辑关系中,需要使用复合逻辑运算,用逻辑运算符来连接多个逻辑语句,复合逻辑运算包含:逻辑与&、逻辑或|、逻辑非~。
逻辑与&
pandas中用符号 & 表示逻辑与,连接两个逻辑语句,同时为真才为真。在Python基本语法中,使用 and 表示逻辑与,但是Pandas中只能用 & ,不能用and,会报模糊错误。
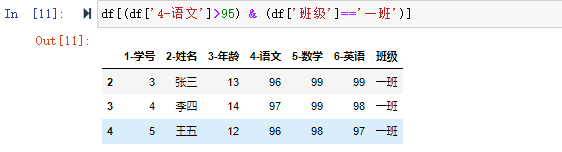
如我们要检索出一班并且语文成绩大于95的数据。可以用 df[(df['4-语文']>95) & (df['班级']=='一班')]
注意两个条件逻辑语句要分别用()括起来然后再用逻辑运算符进行运算。
逻辑或|
pandas中用符号 | 表示逻辑或,连接两个逻辑语句,只要其中一个为真就为真。 在Python基本语法中,使用 or 表示逻辑或,但是Pandas中只能用 | ,不能用or。 如我们要检索出语文成绩大于95或英语成绩大于96的数据
| |
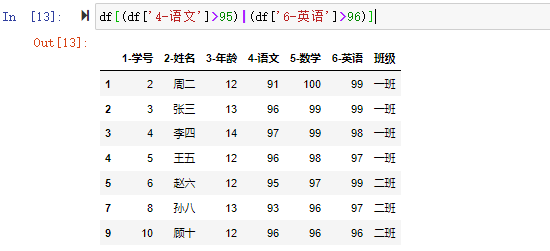
逻辑非~
pandas中用符号 ~ 表示逻辑非,对逻辑语句取反。 在Python基本语法中,使用 not 表示逻辑非,但是Pandas中只能用 ~ ,不能用not。 如我们要检索出数据成绩>98并且不是一班的同学
| |

当然也可以用
| |

二、算术运算
pandas最重要的一个功能是,它可以对不同索引的对象进行算术运算也就是(+、-、*、\)。 常见的算术云算是加法+运算,如果相加的对象是标量,则数据对象通过广播机制,每个数据值都+标量。如果相加的对象是数据对象则按索引进行算术运算。 通过一个数据集来看一下
| |
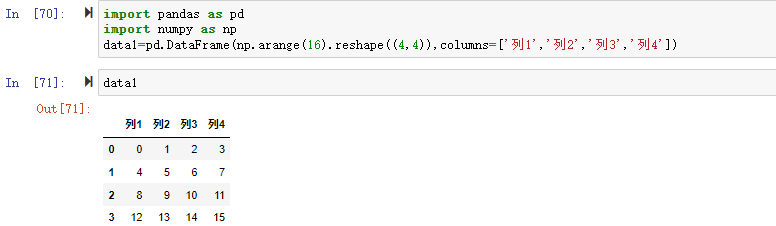
1、使用算术运算符
和标量计算,标量运算会在算术运算过程中传播。
| |
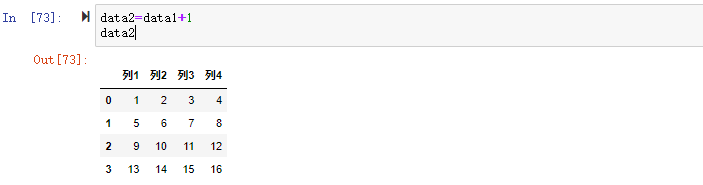 可以看到数据集中每个值都+1了
和索引相同的数据对象运算,对每个数据值进行算术运算
可以看到数据集中每个值都+1了
和索引相同的数据对象运算,对每个数据值进行算术运算
| |
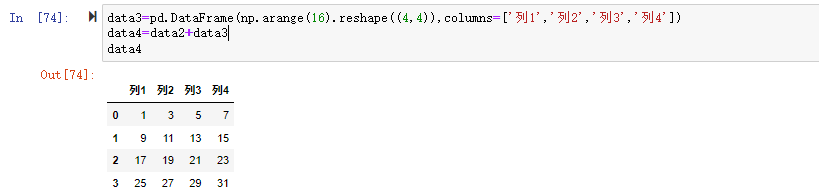
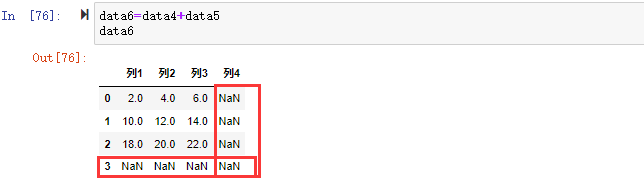
在将对象相加时,如果存在不同的索引就是该索引对的并集。自动的数据对齐操作在不重叠的索引引入NA值。缺失值会在算术运算过程中传播。
| |
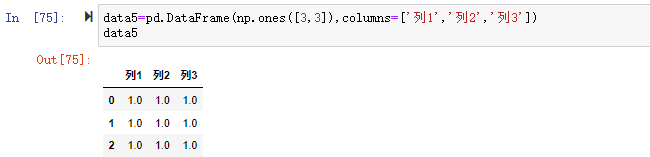
| |
2、使用算数运算函数
算数运算函数包括add、sub、div、mul等对应于算术运算符如下:
| 方法 | 说明 |
|---|---|
| add,radd | 用于加法(+)的方法 |
| sub,rsub | 用于减法(- )的方法 |
| div,rdiv | 用于除法(/)的方法 |
| floordiv,rfloordiv | 用于底除(//)的方法 |
| mul,rmul | 用于乘法(* )的方法 |
| pow,rpow | 用于指数(**)的方法 |
加法:
在对不同索引的对象进行算术运算时,如果希望当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值比如0,可以通过算术方法进行填充,然后再相加。
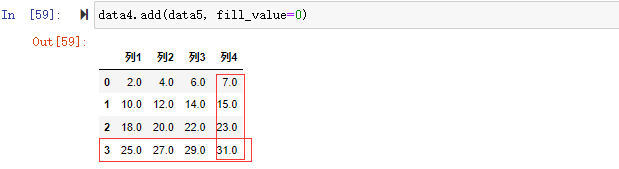 上面的例子展示了,因为data5的行索引为3和列索引为列4用0填充后再相加所以行索引为3和列索引为列4的值是data4的值+0
上面的例子展示了,因为data5的行索引为3和列索引为列4用0填充后再相加所以行索引为3和列索引为列4的值是data4的值+0
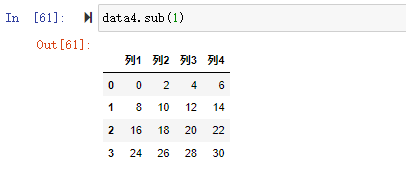
减法:
| |
乘法:
| |
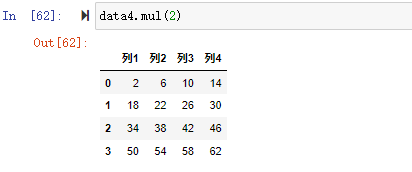
除法:
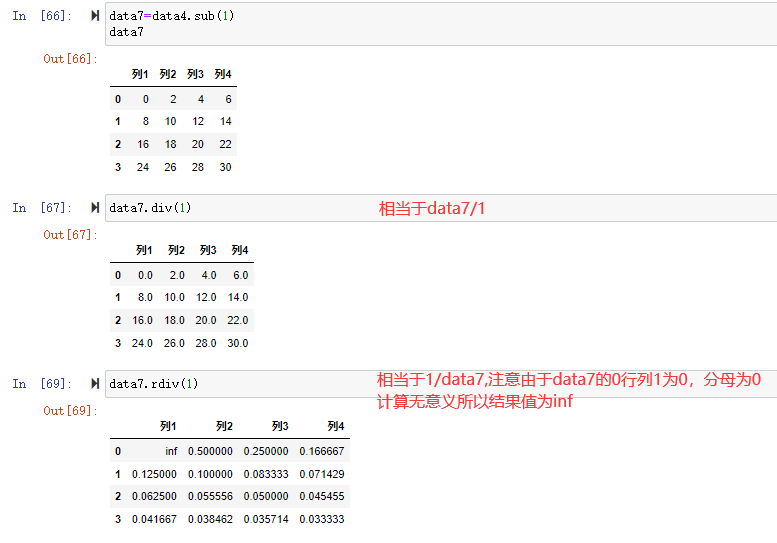
三、统计运算
统计运算就是我们常用的数据集的求和、算平均值、最大值、最小值、绝对值、标准差等统计数据。在pandas中提供了丰富的统计函数可以方便的进行统计运算。
1、describe汇总描述统计
通过np.random.randn(1000,4)生成1000个正态分布的随机数据集看一下describe的汇总描叙统计。 包含了数据个数count、均值mean、标准差std、最小值min、最大值等。
| |
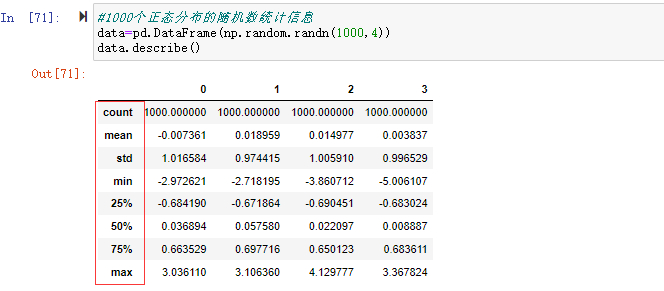
2、统计函数
pandas常用统计函数如下:

| |
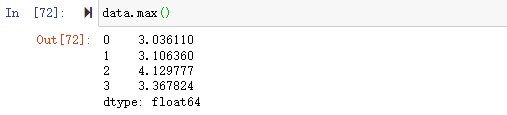
可以算出DataFrame中每一列的最大值
如果只需要计算某一列的最大值
| |

对单个函数进行统计的时候,坐标轴还是按照这些默认为columns(axis=0, default),如果要对index进行统计,则要指明(axis=1) 这里的axis取值与axis=0对应index,axis=1对应columns不同
- 使用0值表示沿着每一列或行标签\索引值向下执行方法
- 使用1值表示沿着每一行或者列标签模向执行对应的方法
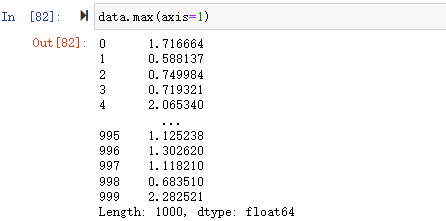
如果要计算某一行的最大值
用data.loc[0].max(),通过loc[]检索出需要统计的行,再用统计函数进行统计
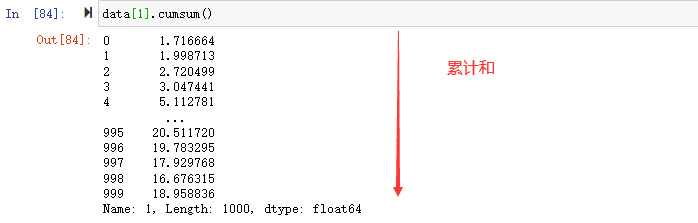
 累计统计cumsum,计算前n个数的和
累计统计cumsum,计算前n个数的和
四、自定义运算
如果常用的统计运算还不能满足,pandas提供了方法可以进行自定义运算。
apply(func, axis=0)
- func – 自定义函数 axis=0 – 默认是列(按行标签方向执行方法)
- axis=1为对行进行运算(按列标签方向执行方法)
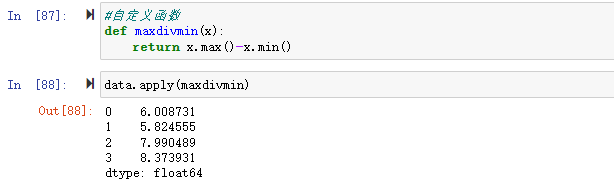
如:自定义一个对列求max-min的函数
 通过lambda匿名函数
通过lambda匿名函数
| |

通过自定义函数
| |
 至此,本文通过实例简单介绍了pandas数据分析的数据运算包括逻辑运算、算术运算、统计运算、自定义运算,也是平时在实际应用中常用的运算。
至此,本文通过实例简单介绍了pandas数据分析的数据运算包括逻辑运算、算术运算、统计运算、自定义运算,也是平时在实际应用中常用的运算。
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!