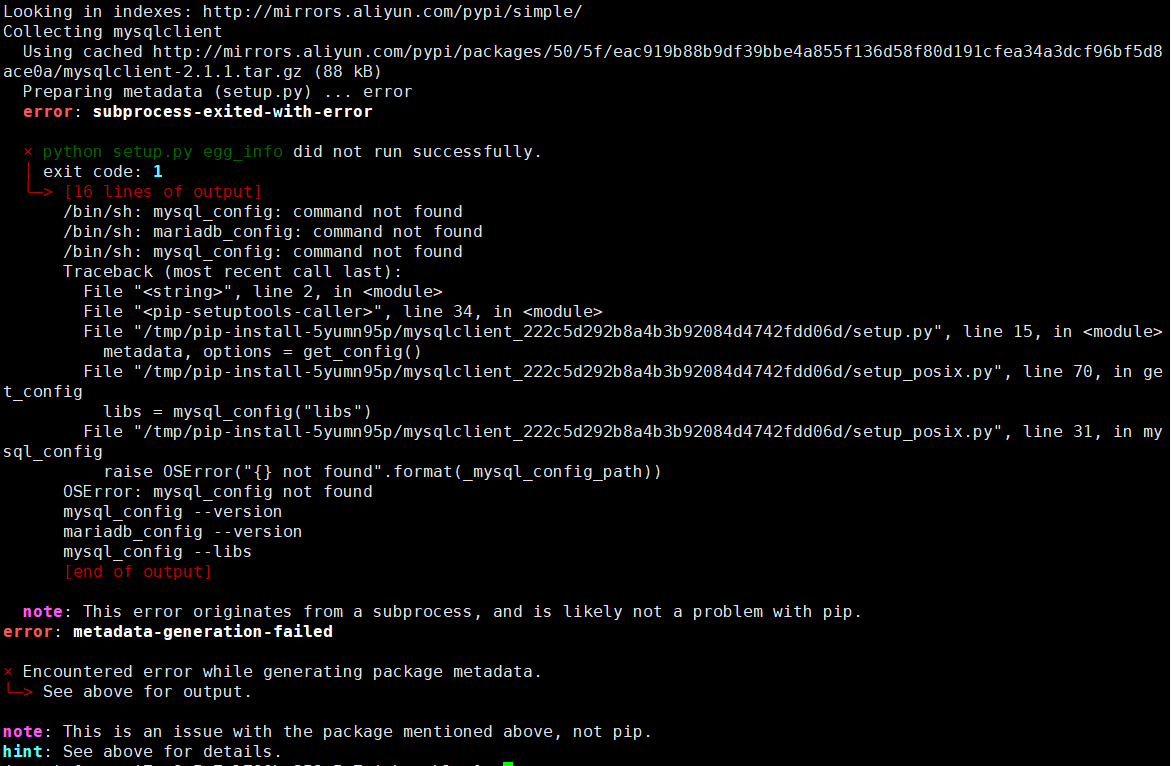
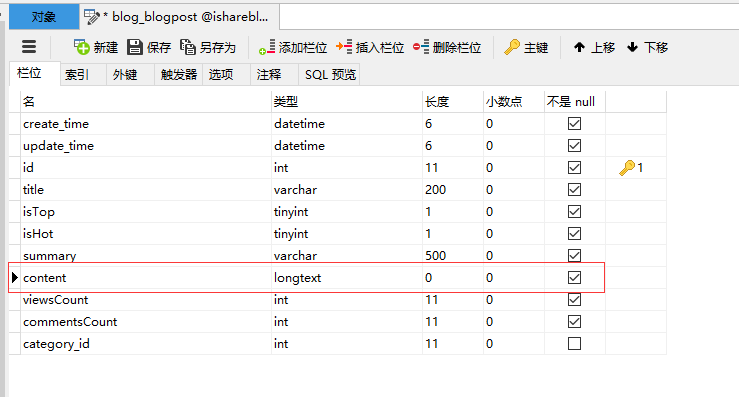
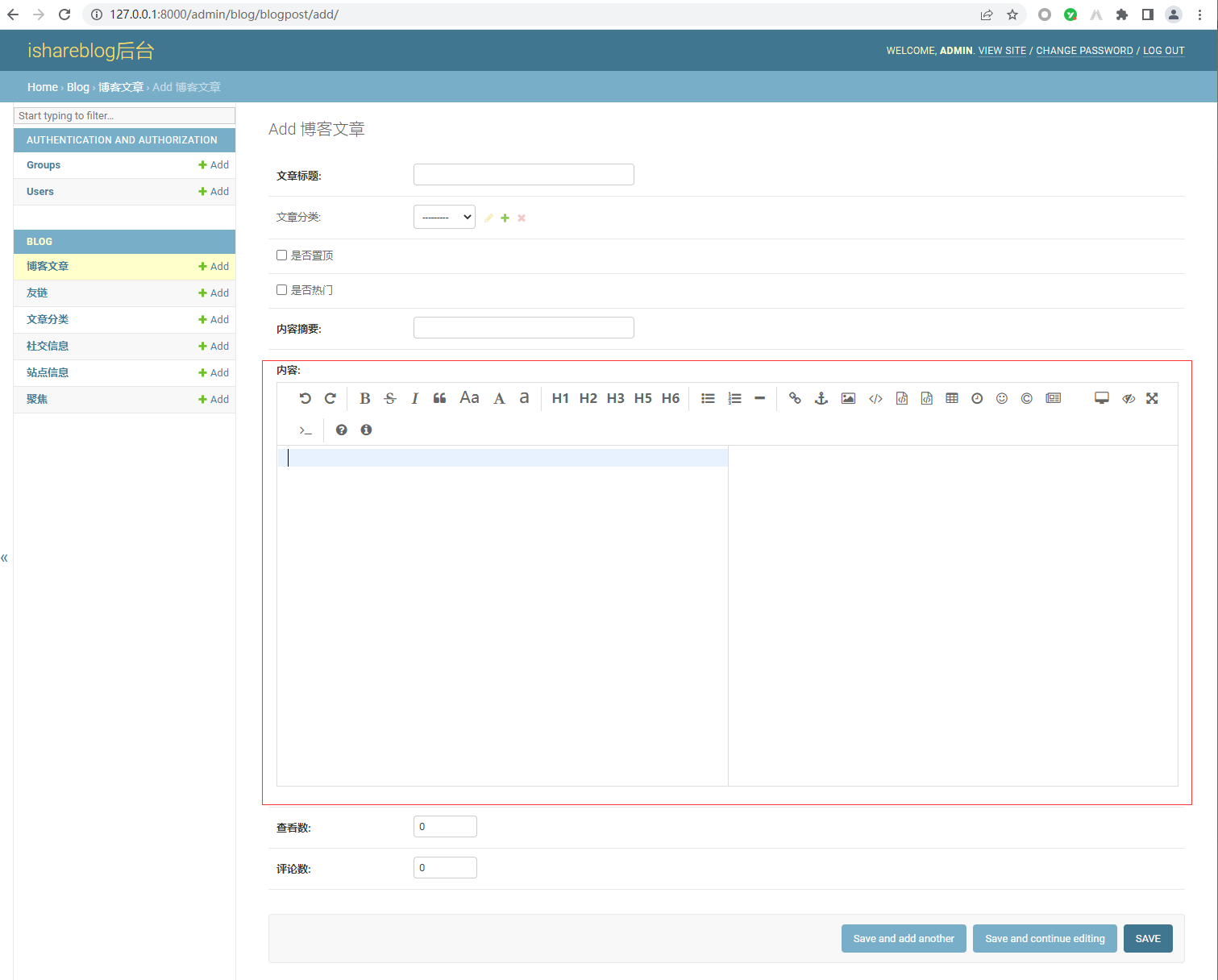
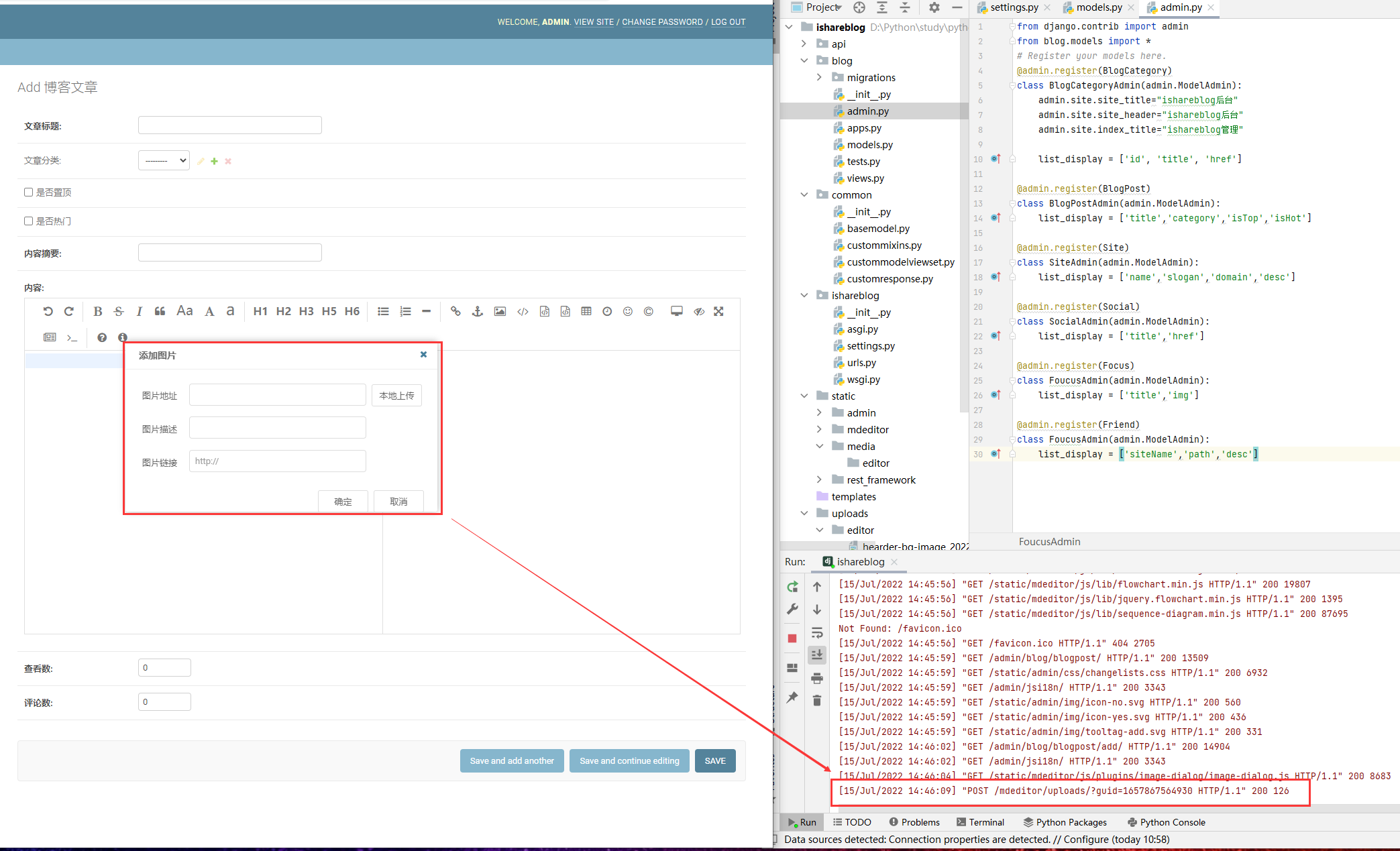
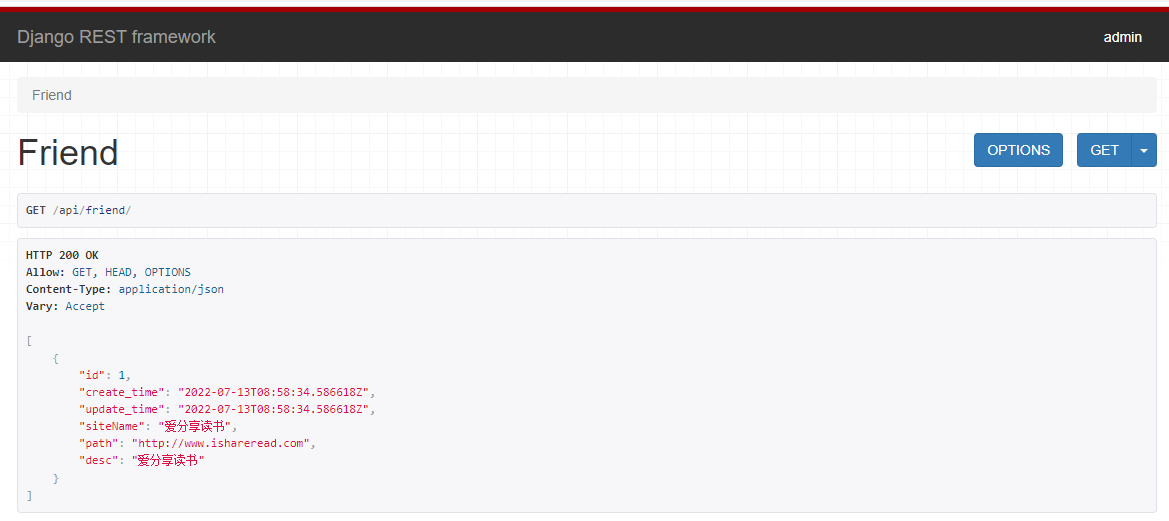
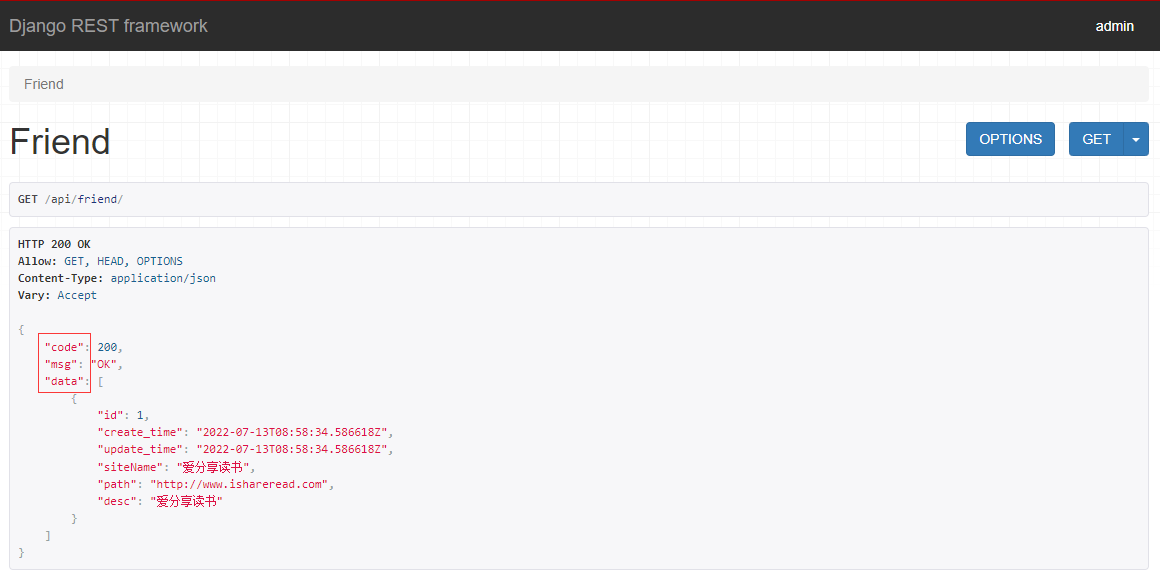
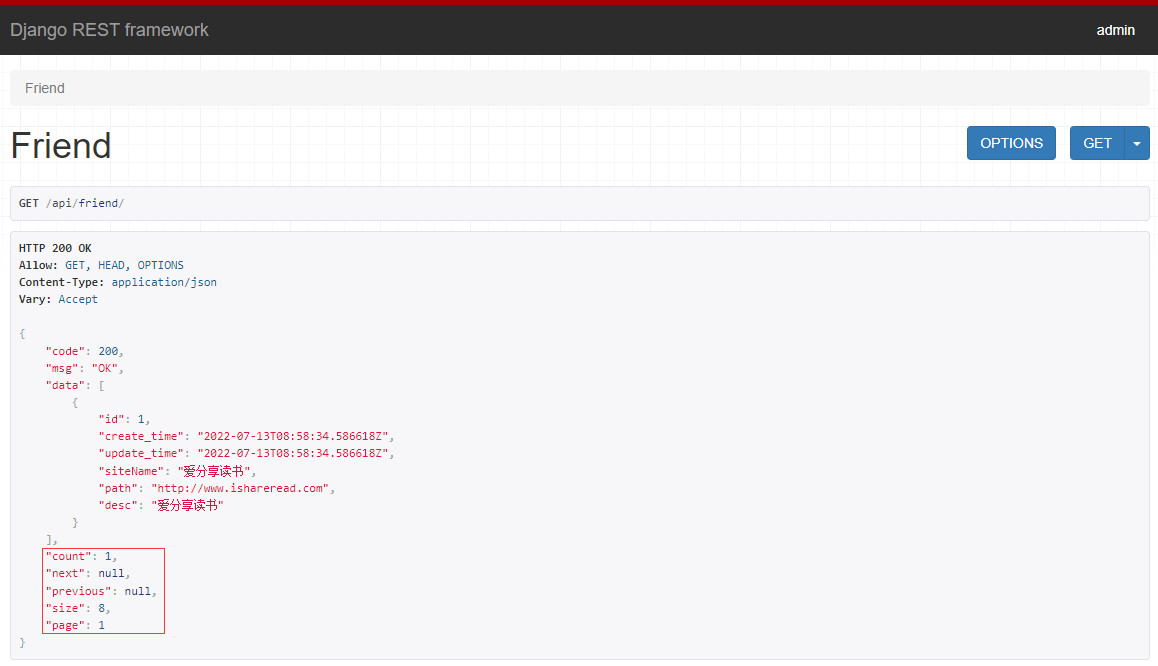
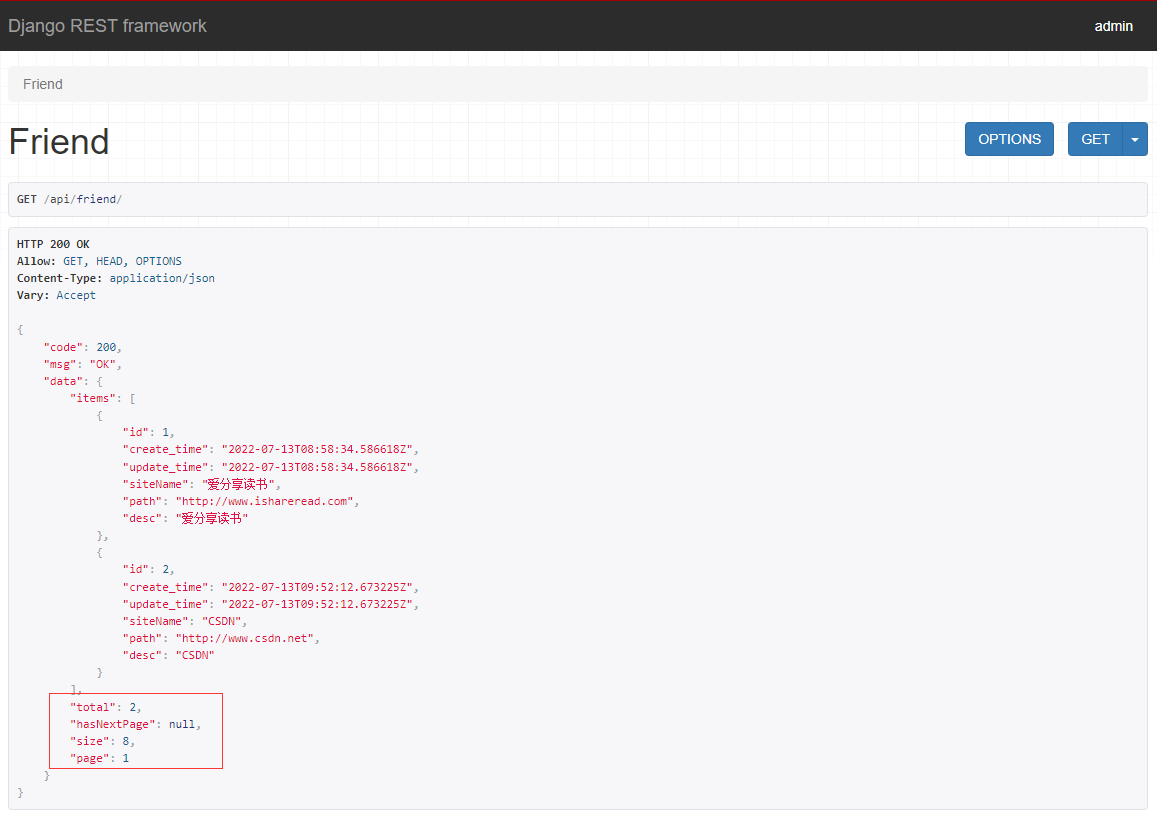
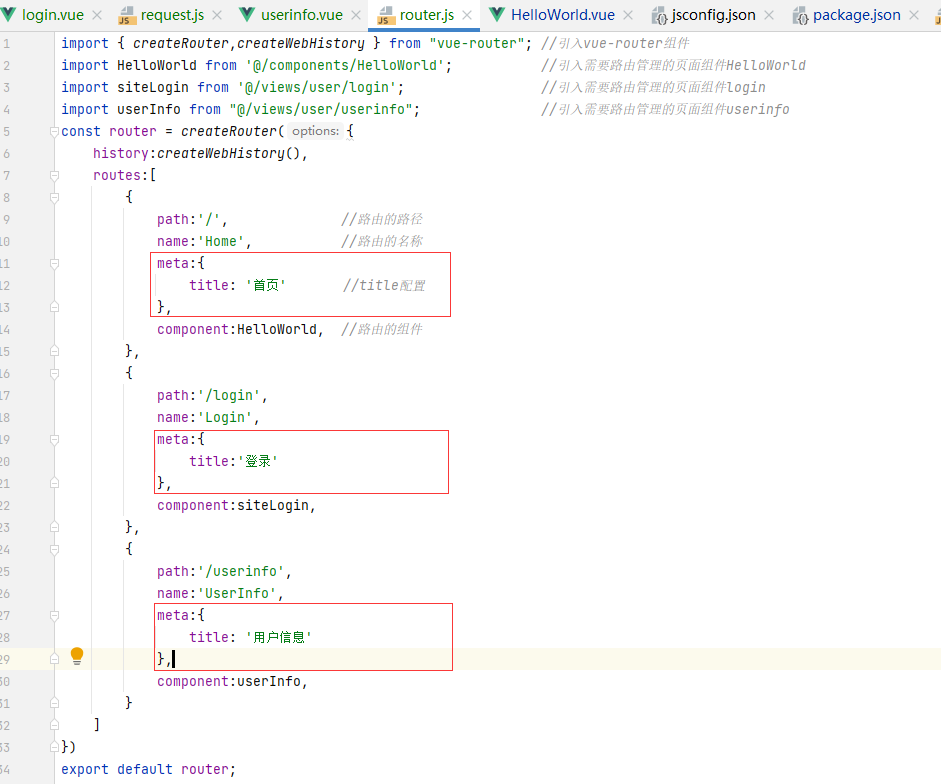
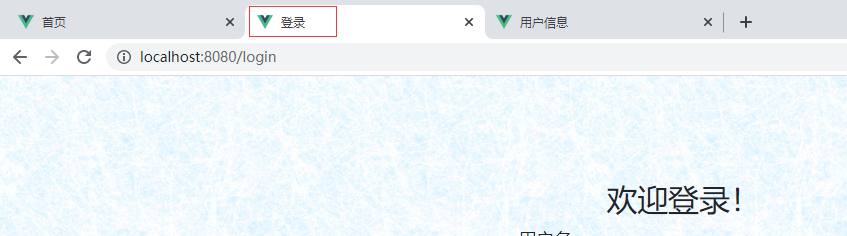
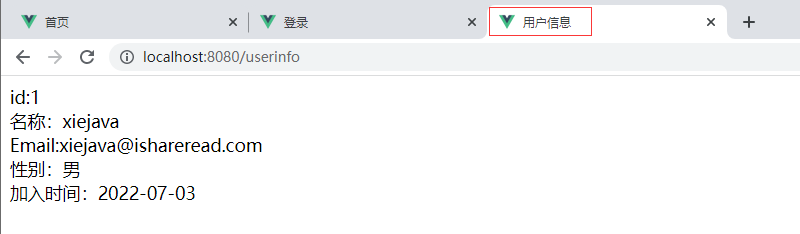
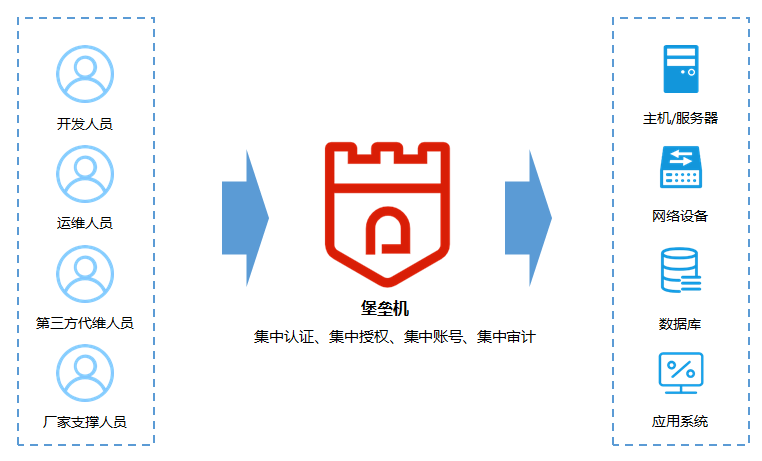
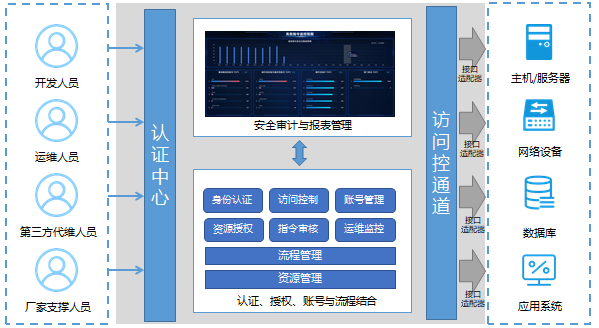
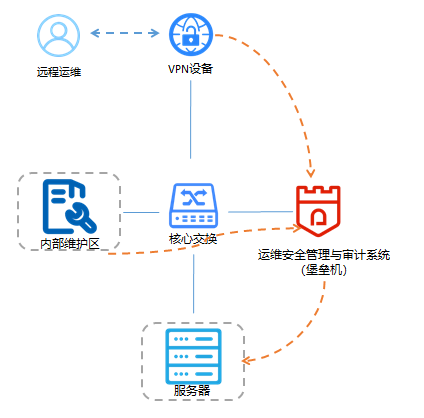
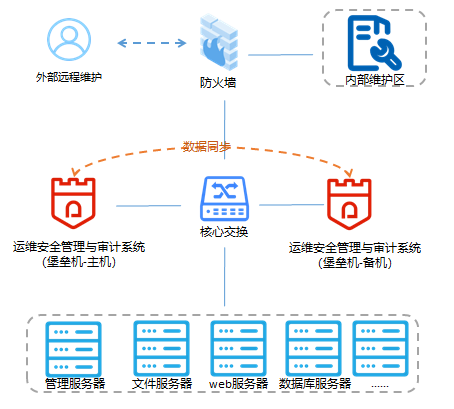
Vue实现博客前端,需要实现markdown的解析,如果有代码则需要实现代码的高亮。
Vue的markdown解析库有很多,如markdown-it、vue-markdown-loader、marked、vue-markdown等。这些库都大同小异。这里选用的是marked,代码高亮的库选用的是highlight.js。
具体实现步骤如下:
一、安装依赖库
在vue项目下打开命令窗口,并输入以下命令
1 | npm install marked -save // marked 用于将markdown转换成html |
命令执行完后可以在控制台或package.json文件中看到有安装的版本号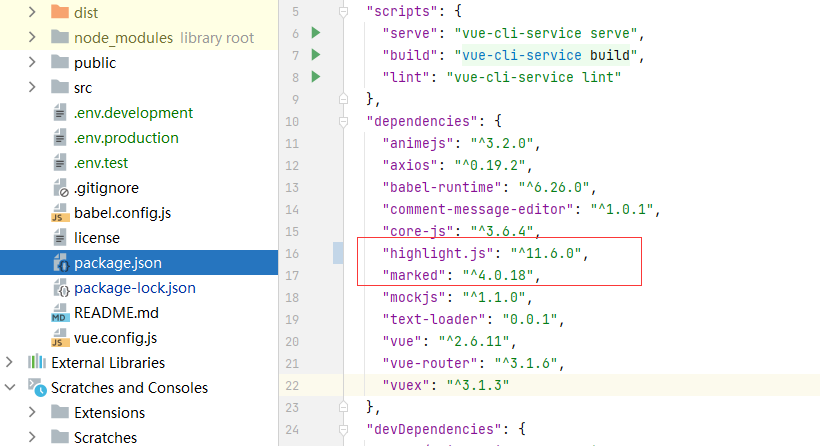
二、在main.js文件中引入highlight.js及样式并创建一个自定义的全局指令
1 | import hljs from 'highlight.js'; |
这样就可以在vue组件中使用v-highlight引用代码高亮的方法了。
三、在Vue组件中应用marked解析及实现代码高亮
代码示例如下:
1 | <!-- 正文输出 --> |
1 | <script> |
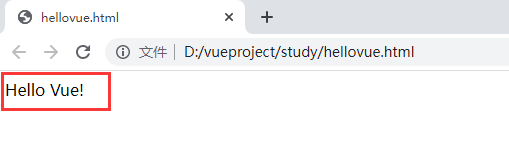
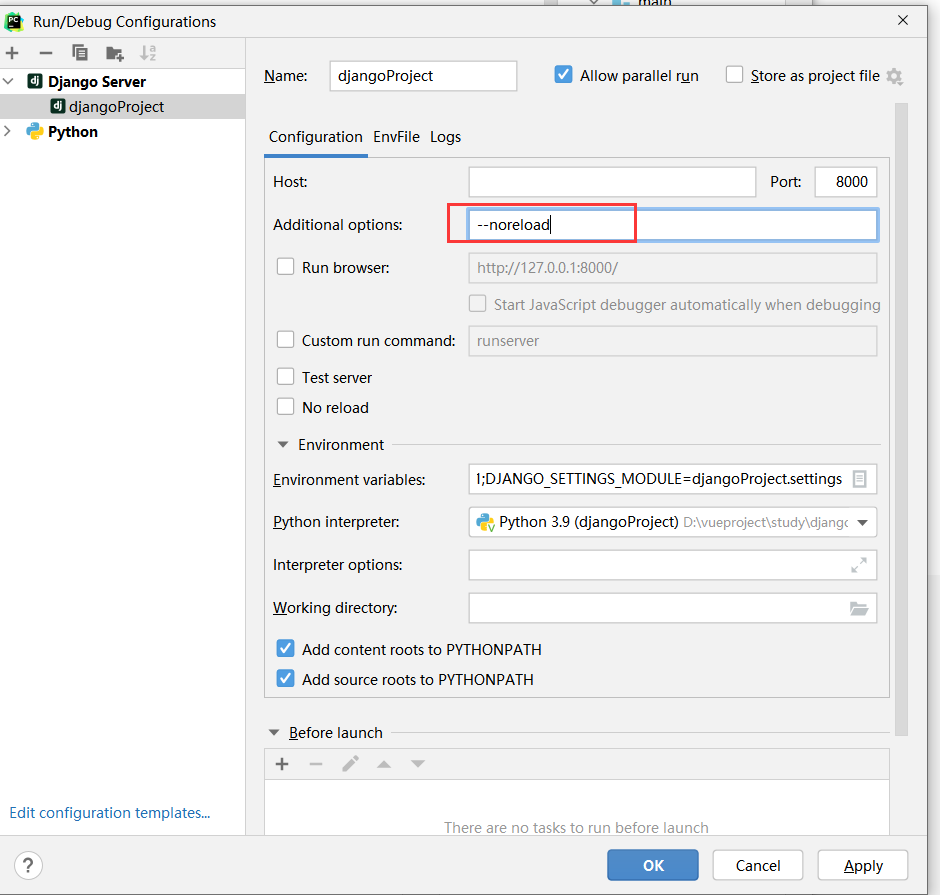
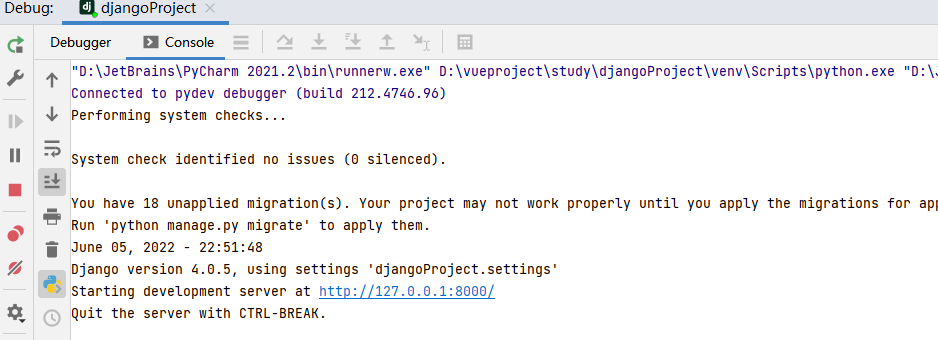
四、显示效果
markdown解析及代码高亮显示效果
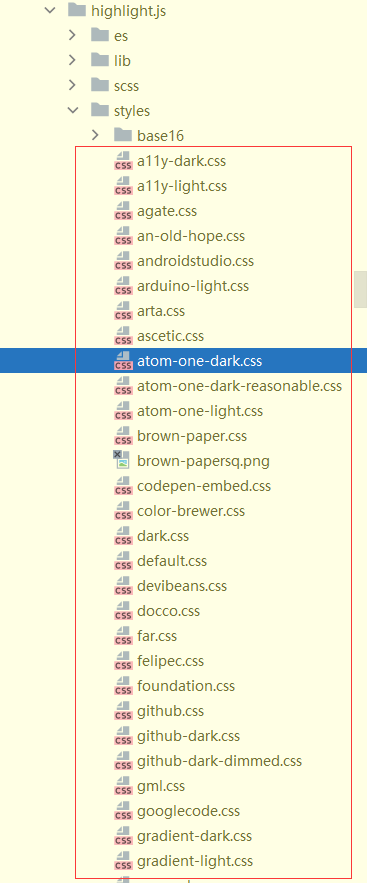
示例中引用的样式是 import 'highlight.js/styles/atom-one-dark.css'
实际highlight.js/styles中提供了很多样式,可以根据自己的喜好选用。
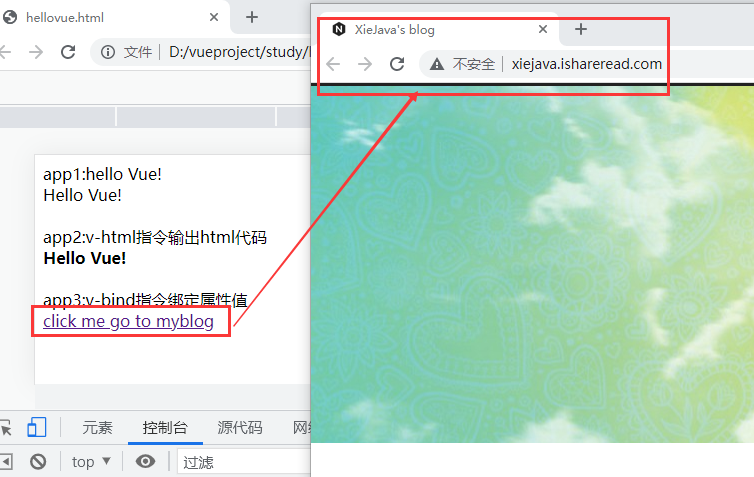
博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!