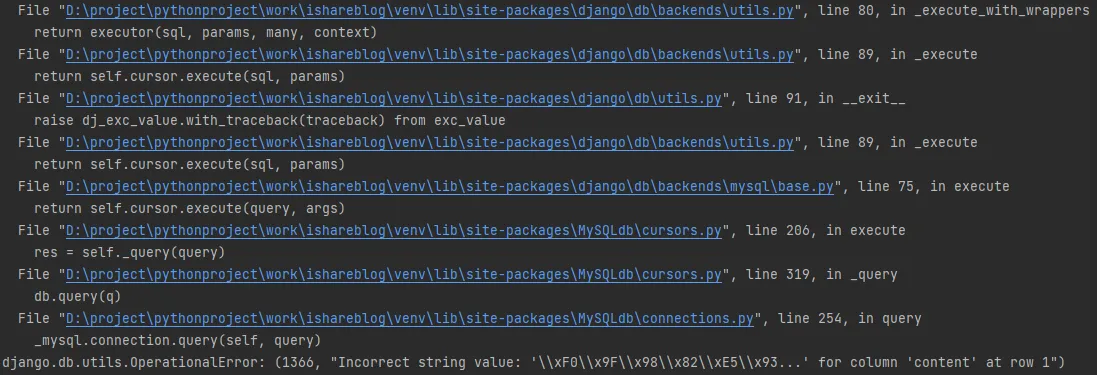
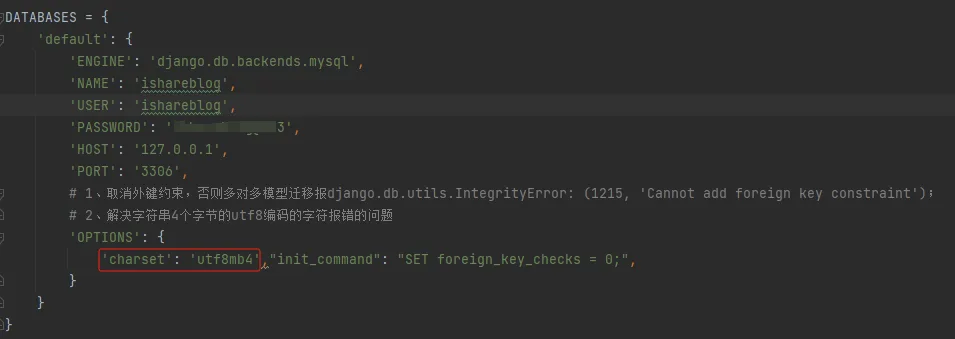
今天在尝试用pytest进行django的单元测试,pytest用的数据库是sqlite3,在window环境下测试得好好的,但是放到linux环境下就报错,具体是报django.core.exceptions.ImproperlyConfigured: SQLite 3.9.0 or later is required (found 3.8.2).的错。
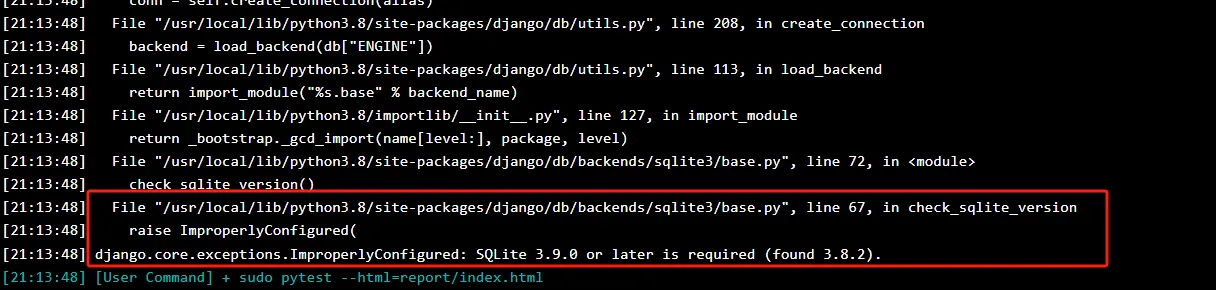
从报错的提示看是sqlite3的版本太低,期望是3.9.0但是当前版本是3.8.2
在网上找了很多资料,也都是说django与sqlite3的版本不兼容,需要升级sqlite3的版本。
于是将sqlite3升级到目前的稳定版本3.46.0,然而发现并没有什么用,还是报sqlite3.NotSupportedError: deterministic=True requires SQLite 3.8.3 or higher 。
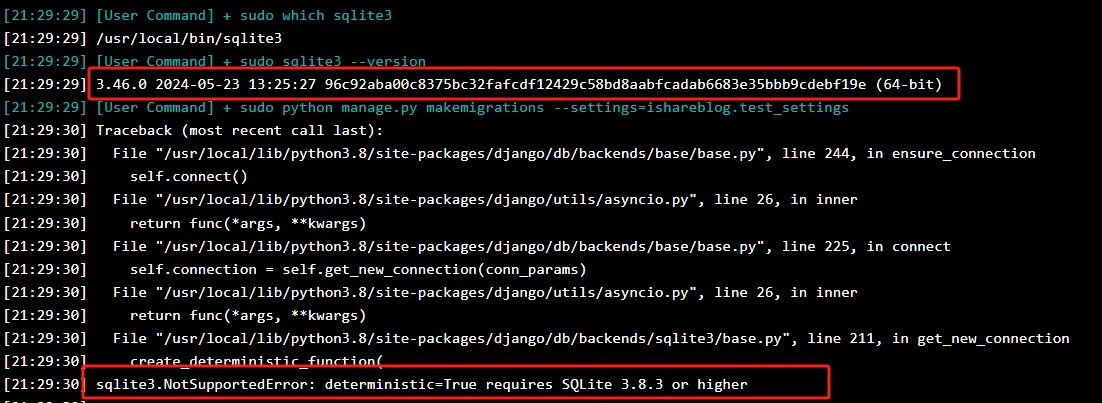
通过sqlite3 –version 查看版本号已经是3.46.0了,但还是提示要求SQLite版本在3.8.3以上。重装django4和python3.8的环境都没有用。
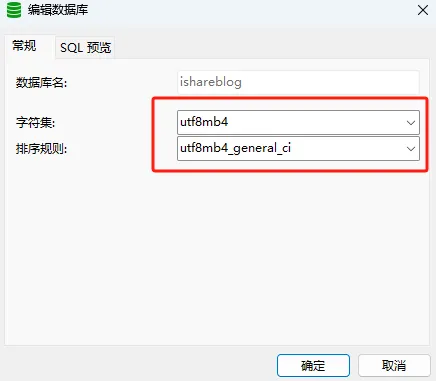
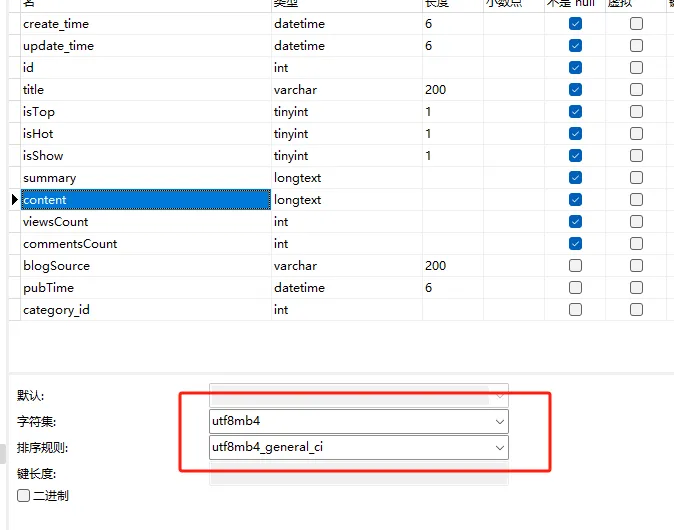
最后在网上找到解决办法。使用第三方包pysqlite3运行SQLite3
具体方法如下:
1、安装pysqlite3和pysqlite3-binary
1 | pip install pysqlite3 |
2、找到django的sqlite3驱动包,/usr/local/lib/python3.8/site-packages/django/db/backends/sqlite3/base.py 找到 from sqlite3 import dbapi2 as Database 注释它,添加代码
1 | #from sqlite3 import dbapi2 as Database #注释它 |
历经周折终于解决。
博客地址:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!