这是知识库系列的应用篇。前几篇写了怎么部署(WeKnora)、怎么养(LLM Wiki)、怎么写(Claude Code + RAG)。这一篇回答一个更朴素的问题:Claude Code 是命令行驱动的,但大多数人不碰终端——怎么把"本地 Obsidian + 企业 WeKnora + 云端 ima/Notion/飞书"这三类知识库也交给普通员工用? 答案是
scheme-writer这个 skill + workbuddy 这样的 GUI Agent。同一个 skill,同一套脚本,能装进 CLI Agent 也能装进 GUI Agent,三库打通的本质——是 skill 而不是 Agent。
一、知识库建好了,然后呢?
很多人对知识库的期待是这样的:建好库、灌进文档,然后对着 AI 说一句"帮我查一下漏洞管理流程",AI 就该乖乖去检索、给出带出处的回答。
现实是:大多数 AI Agent 并不会主动去用你那个知识库。它们不知道你的知识库在哪、不知道用什么 API、不知道怎么认证、不知道检索结果该怎么用。你把 WeKnora 部署在 http://<your-server-ip>,Agent 对此一无所知。
于是出现了一个尴尬的局面:知识库在那一头孤零零地等着被问,Agent 在这一头不知道门在哪。
更尴尬的是,知识库往往不止一个:
- 本地知识库——我用 Obsidian 维护的个人/团队笔记(Markdown 文件,躺在磁盘上);
- 企业内部专用知识库——比如上一篇部署的 WeKnora,存的是制度、规范、客户文档;
- 云端知识库——腾讯 ima、Notion、飞书文档,或者公有云的 RAG 服务。
这三个库各管一摊,Agent 要用它们得分别学三套玩法。这正是 skill 这种东西该解决的问题。
我写了一个叫 scheme-writer 的 skill,目标很朴素:给 Agent 装上一个"知识库遥控器",让它用一套统一的方法,操作本地、云端、企业内部这三类知识库。
二、scheme-writer 是什么
一句话:它是一个可以装进任何支持 skill 的 AI Agent 里的知识库操作技能。
支持 skill 机制的 Agent 现在越来越多——Claude Code、workbuddy、Trae Solo 都能加载 skill。scheme-writer 就是一组 Markdown 说明(SKILL.md)加上几个 Python 脚本,丢进 Agent 的 skills 目录就能用。
它给 Agent 提供了五个核心能力:
| 能力 | 作用 | 典型触发 |
|---|---|---|
| 知识库语义检索(kb_search) | 按问题从指定库拉相关片段 | “从《技术规范库》查一下…” |
| 知识库列表(kb_list) | 列出当前账号可见的所有库 | 用户没指定用哪个库时 |
| 库内文档清单(kb_docs) | 看某个库里到底有哪些文档、解析状态如何 | “库里有什么"“为什么搜不到” |
| 文档上传归档(kb_upload) | 把写好的内容上传回知识库 | “把这份方案归档到《方案库》” |
| 首次配置(init) | 对话内引导配置 URL / 密钥 / 别名 | 第一次使用或重新配置 |
这五个能力拼起来,就构成了一个完整的”检索 → 写作 → 归档“闭环:Agent 从知识库拉素材、整理成方案、再写回知识库沉淀。知识不再是单向消费,而是能持续积累。
三、整体架构:如何协同打通三类库
scheme-writer 真正解决的不是"Agent 怎么连一个库”,而是"Agent 怎么用一套语言同时管三类库"。下面这张图展示了这个协同关系:
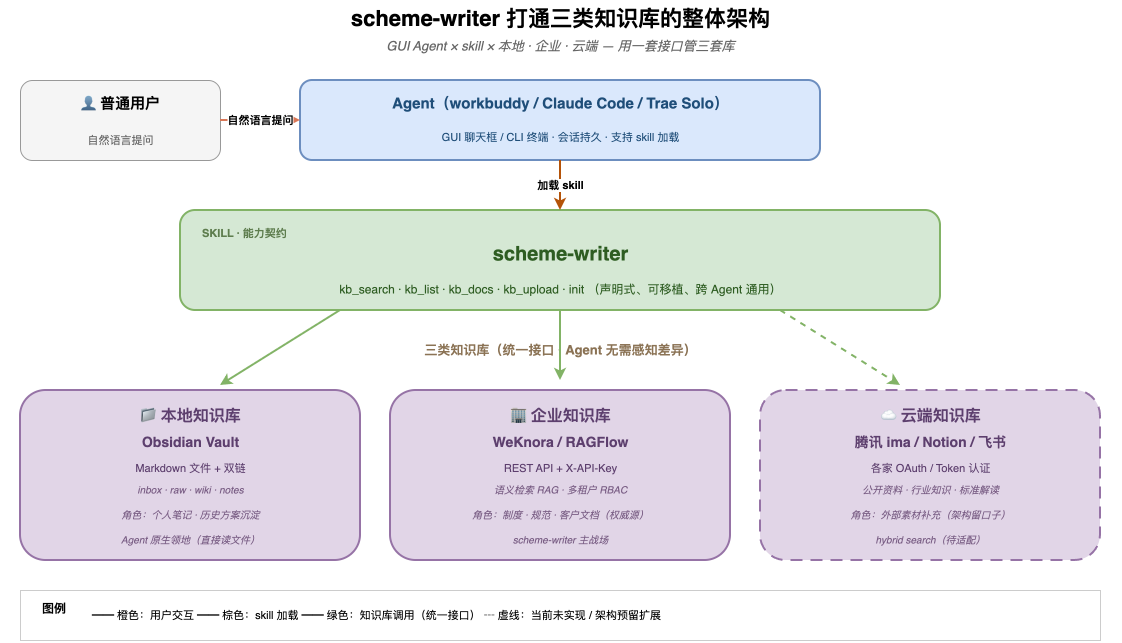
这条链路上有 4 类角色:
- 👤 用户:在 GUI 聊天框 / CLI 终端里说一句自然语言,不必懂任何知识库技术
- 🤖 Agent(workbuddy / Claude Code / Trae Solo):把用户的自然语言翻译成对 skill 的一组调用——它本身也不需要知道三类库的差异
- 🧩 scheme-writer skill:5 个 Python 脚本,对外暴露 5 个原语,对内统一调度三类库——这是真正的"翻译官"
- 🗄️ 三类知识库:本地 Obsidian / 企业 WeKnora / 云端 ima/Notion/飞书——它们形态各异,但通过 skill 暴露的能力是统一的
最关键的耦合点:scheme-writer 同时连三类库,但它只在内部知道差异——Agent 调 kb_search 时,根本不用关心这次检索的是磁盘、REST API 还是 OAuth。这就是"打通"的本质:用 skill 在 Agent 和三类库之间做一层适配,让上游和下游互相不知道彼此的细节。
三类库在体系里的角色
三类库不是对等的并列关系,而是互补的角色分工:
| 库类型 | 协议 | 在体系中的角色 | 用户心智模型 |
|---|---|---|---|
| 本地 Obsidian | 文件系统直读 | 个人笔记沉淀池 + 历史方案归档 | “我自己的资料” |
| 企业 WeKnora | REST + X-API-Key | 权威素材源(制度、规范、客户文档) | “公司的知识” |
| 云端 ima / Notion / 飞书 | OAuth/Token | 外部公开资料 + 行业知识补充 | “外面的资料” |
scheme-writer 的检索策略会自动加权这三类源:默认重企业库(最权威)+ 本地库(最相关个人资料)+ 可选云端库(补全外部信息)。用户在对话框里感受不到这三层,他只觉得"AI 什么都知道"。
这张图想说明的事
如果你只看这张图,记得住一句话就够了:scheme-writer 把"Agent 调用一个库"这件事,变成"Agent 调用一类库"——而 Agent 自己不知道这是怎么做到的。 这就是 skill 作为适配层的真正价值。
四、核心卖点:跨 Agent 可移植
skill 这种形态有个被低估的好处:它是声明式的。
一个 skill 就是一个 SKILL.md(告诉 Agent “什么场景下用什么脚本、按什么规则”)加若干脚本。它不依赖某个特定 Agent 的私有 API,只要 Agent 支持"加载 skill 目录 + 执行脚本"这套机制,就能用。
这意味着——scheme-writer 不是某个 Agent 的私货,而是跨 Agent 通用的工具包:
| Agent | 类型 | 用 scheme-writer 的方式 |
|---|---|---|
| Claude Code | CLI(开发者) | cp -r scheme-writer ~/.claude/skills/ |
| workbuddy | GUI(普通员工) | 拖到 workbuddy 的 skills 目录,对话框直接说"写份漏洞方案" |
| Trae Solo | 轻量 GUI | 同上 |
| Cursor Composer | IDE 内嵌 | 加载 skill 即可 |
| 未来任何支持 skill 协议的 Agent | 任意 | 同一份脚本、同一份 SKILL.md,零迁移成本 |
我在 workbuddy 上跑过 scheme-writer——普通业务人员打开 GUI 聊天框,说一句"帮我查一下企业库里最新的漏洞管理办法",AI 自动调 kb_search,给出带出处的回答。整个过程他们不知道 WeKnora 是什么,不知道 X-API-Key 是什么,也不知道 RAG 是什么——但企业知识库真正"被用起来了"。
对企业来说这点很关键:Agent 工具会换(今天是 Claude Code,明天可能是 workbuddy 或某个国产 Agent),但"怎么用知识库"这套方法论和配置不该绑死在某个 Agent 上。你写一次 skill,换 Agent 不用重学。
五、一次完整的三库协作(时序图)
下面这张时序图展示了用户说一句"写一份漏洞管理方案"之后,scheme-writer 怎么把"本地 + 企业 + 云端"三类库串起来跑完整个流程:
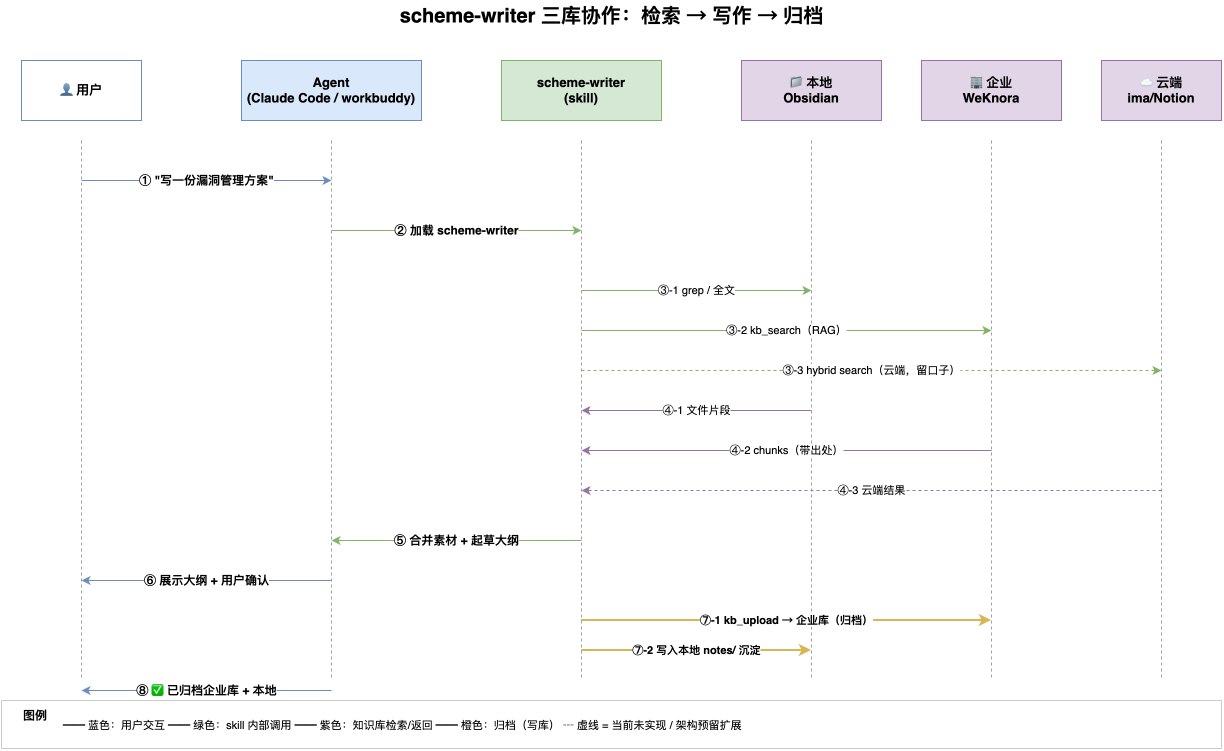
8 个步骤:
- 用户提问——一句"写一份漏洞管理方案"
- Agent 加载 skill——
scheme-writer的 5 个脚本就位 - 并行检索三类库——同时打本地(grep + 全文)、企业(kb_search / RAG)、云端(hybrid search,留口子)
- 三类库各自返回——本地片段 / 企业 chunks(带出处) / 云端结果
- Agent 合并素材——综合三路结果去重、排序,整理为可写作的结构
- 展示大纲让用户确认——用户点头才展开成完整方案
- 双轨归档——同时写回企业库
kb_upload、沉淀到本地notes/ - 完成提示——“已归档到企业库 + 本地”
关键设计:归档前的"确认"动作绝不省略。 在企业场景,“误上传"和"漏上传"一样麻烦。
六、本地 / 企业 / 云端三类库,分别怎么用
6.1 本地知识库:Agent 的原生领地
本地知识库(比如我的 Obsidian vault)对 Agent 来说是"主场”——文件就是磁盘上的 Markdown,Agent 天生能读、能写、能搜索。这部分不需要 skill 介入,Agent 用自带的文件工具就能搞定。
但问题是:本地库的检索是关键词级的,不是语义级的。 Agent 用 grep 搜"漏洞管理",只能命中字面包含这四个字的文件;它没法像 RAG 那样理解"高危漏洞多久要修"的语义。
所以 scheme-writer 给本地库的角色定位是:素材沉淀池 + 个人笔记。检索主要靠企业库(语义),写作完后回写到本地作为"我的归档"。
6.2 企业内部知识库:scheme-writer 的主战场
企业库(WeKnora / RAGFlow 这类)有真正的语义检索能力,但藏在 API 后面。Agent 要用它,得知道:
- 端点地址(
/api/v1/knowledge-search) - 认证方式(
X-API-Key头,不是常见的Bearer Token) - 请求体结构(
query、knowledge_base_id、top_k、min_score) - 响应字段(不同版本字段名还不一样:
chunks/results/data)
这些细节如果让 Agent 每次"临时查文档 + 手写 curl",既慢又容易错。scheme-writer 把这些全部封装好了:Agent 只需要说"检索漏洞管理",skill 内部处理好所有 API 细节、字段兼容、错误归一化。
6.3 云端知识库:架构可扩展
云端库(ima / Notion / 飞书)各有各的 API。scheme-writer 当前的主实现对接的是 WeKnora 协议,但它的设计是可插拔的知识库后端——只要某个云端库暴露了"检索/列表/上传"这几个原语,就能用同一套 skill 接口接入。
这也是为什么 scheme-writer 的 kb_http 设计成独立的统一客户端:新的云端适配只需要实现"它自己的协议 → kb_http 标准接口"那一层,skill 上层完全不动。
七、实战:一次完整的三库协作
把上面这些拼起来,看一个真实的协作流程。假设需求是:“帮我从企业知识库查漏洞管理相关制度,写一份漏洞管理方案,写完归档到方案库,同时把要点记到我的本地笔记。”
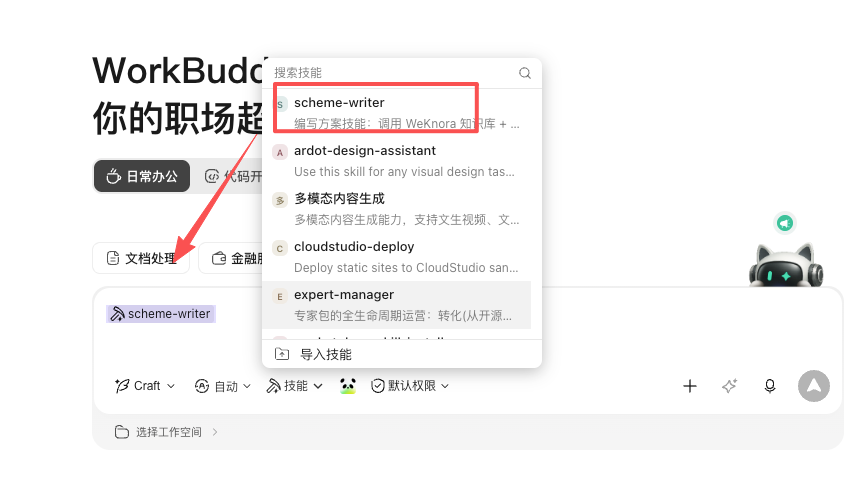
1、为workbuddy装上scheme-writer
在 https://github.com/xiejava1018/myopenclaw-skills/tree/master/scheme-writer 下载scheme-writer技能
 在workbuddy中导入技能
在workbuddy中导入技能
导入成功就可以在wrokbuddy中使用了
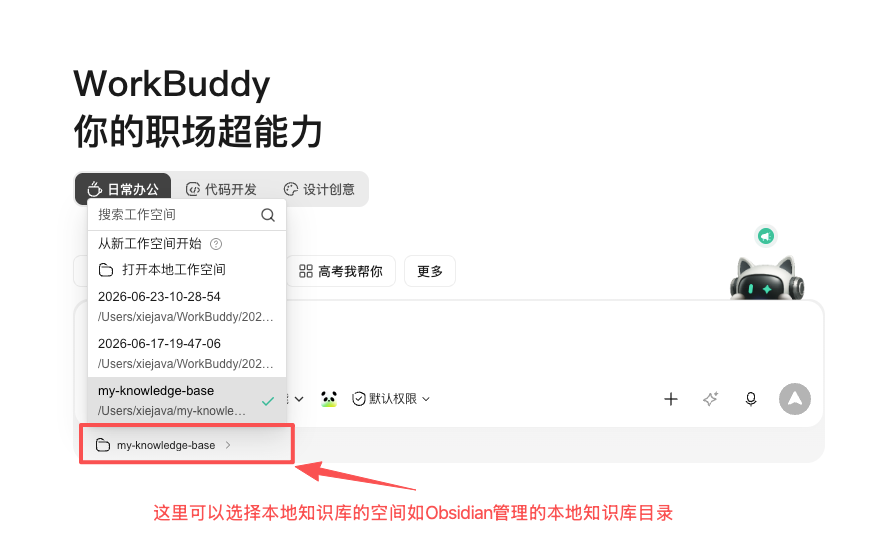
2、为workbuddy配置好本地知识库工作目录和云端库
可以配置工作空间工作目录为Obsidianguan管理的本地知识库目录
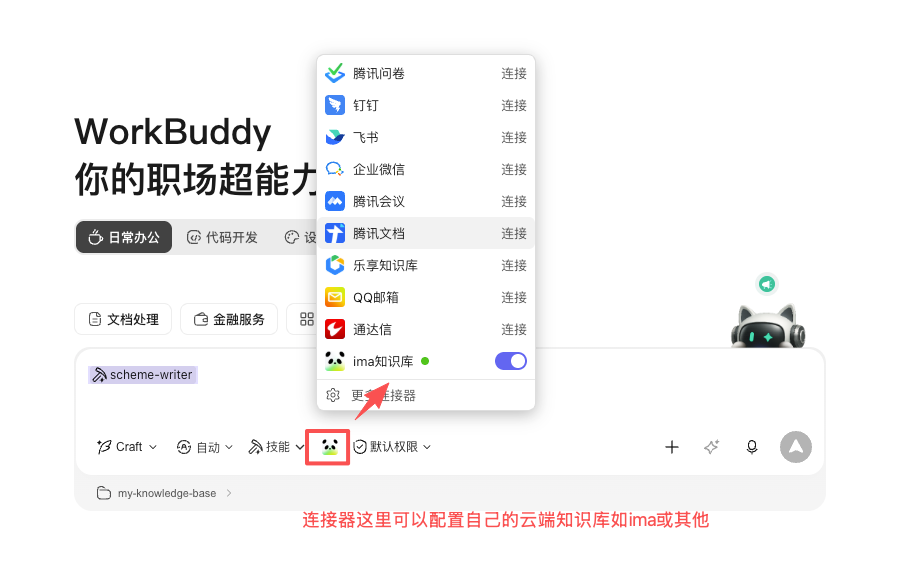
 可以通过连接器配置自己的云端知识库如ima或其他
可以通过连接器配置自己的云端知识库如ima或其他
 3、给workbuddy下指令
3、给workbuddy下指令
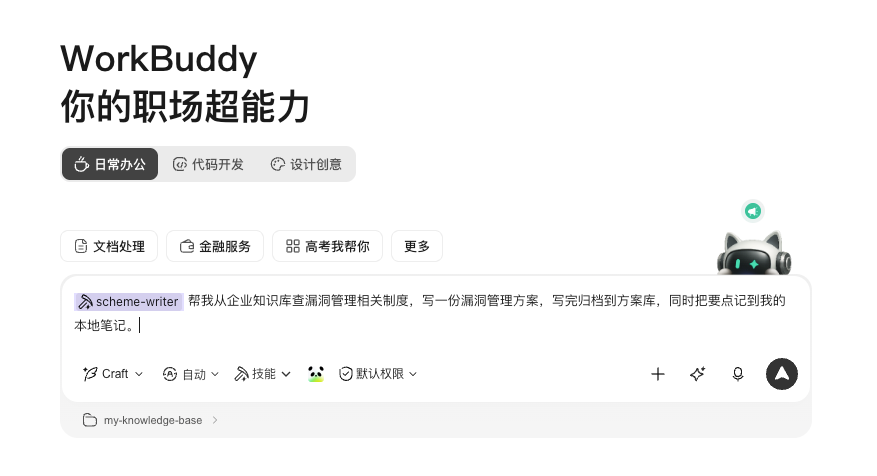
Agent 会这样跑:
- 检索企业库:调
kb_search,从 WeKnora 拉出漏洞管理制度的相关片段(带相似度分数,低于阈值的丢弃); - 补充本地库:用文件搜索看看本地 Obsidian 里有没有相关的个人笔记或历史方案,作为补充素材;
- 云端补充(可选):如果用户指定了云端库(ima 上的行业标准解读),调云端的 hybrid search 拉外部素材;
- 写作:综合多路素材,先出大纲、确认后展开成完整方案;
- 归档企业库:上传前确认,调
kb_upload把方案写回《方案库》; - 沉淀本地库:把方案要点存成本地 Markdown 笔记,建好双链。
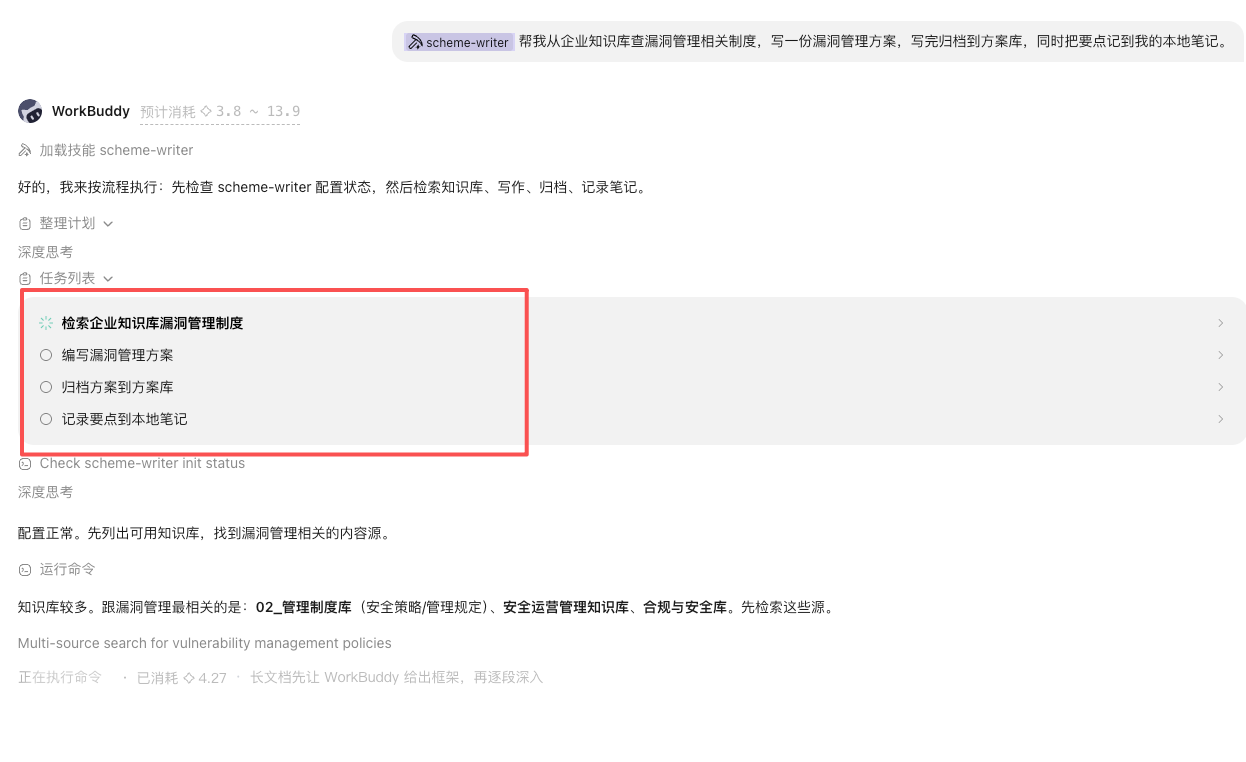
可以看到workbuddy AI agent执行了全流程的任务形成了方案并保存到了企业知识库将方案要点又保存到了本地知识库。
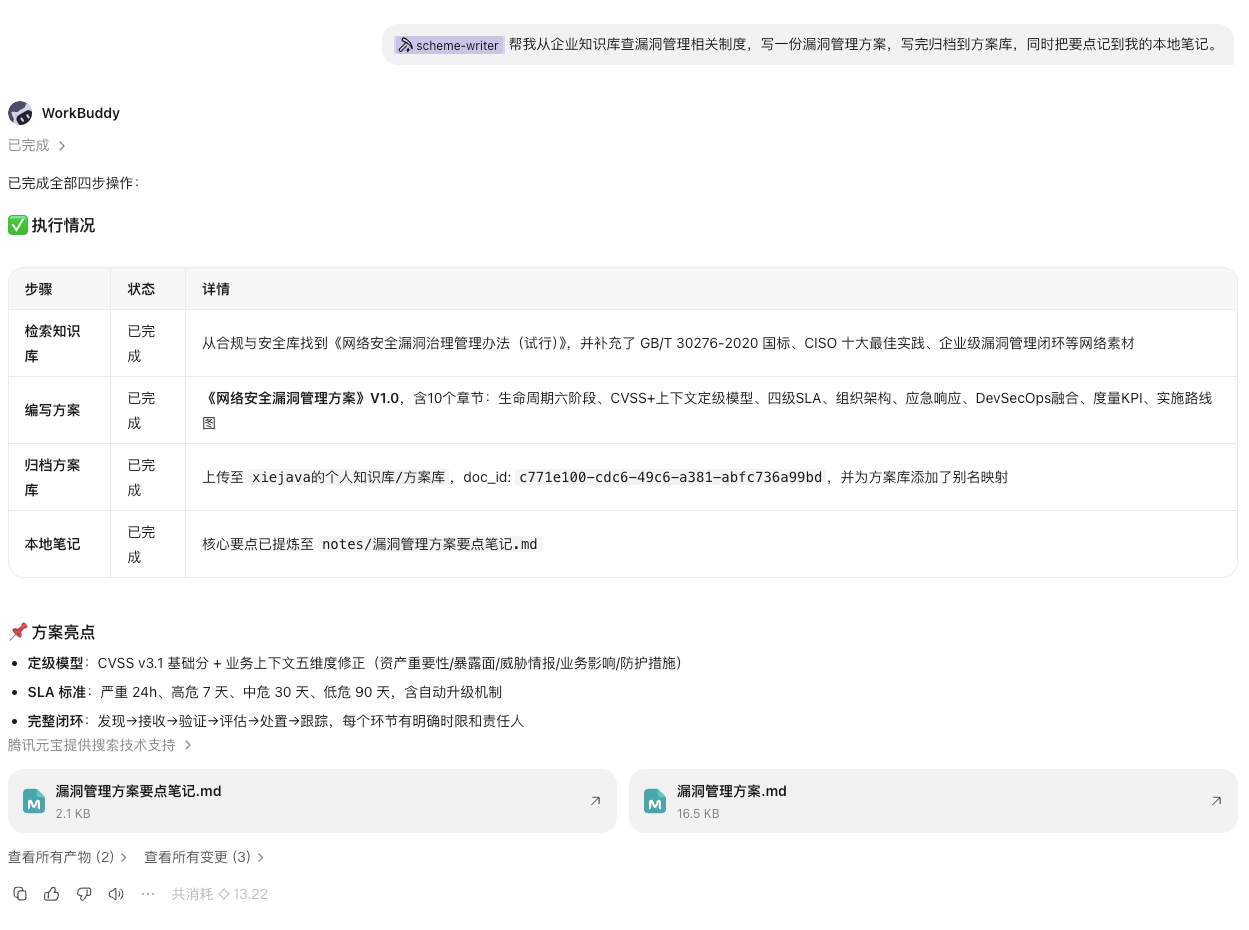
归档到企业库的方案文档
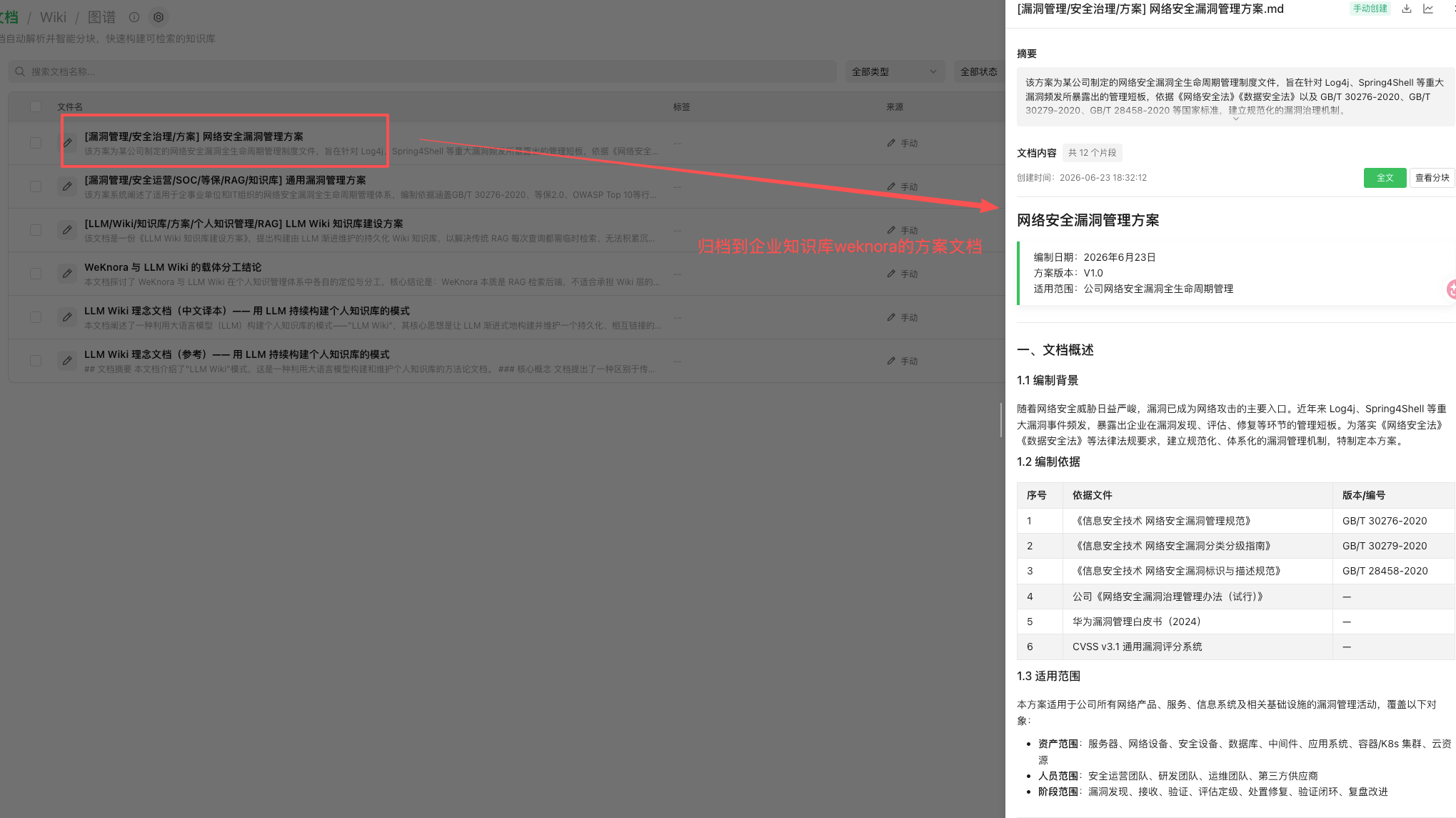
沉淀到本地库的存档和摘要
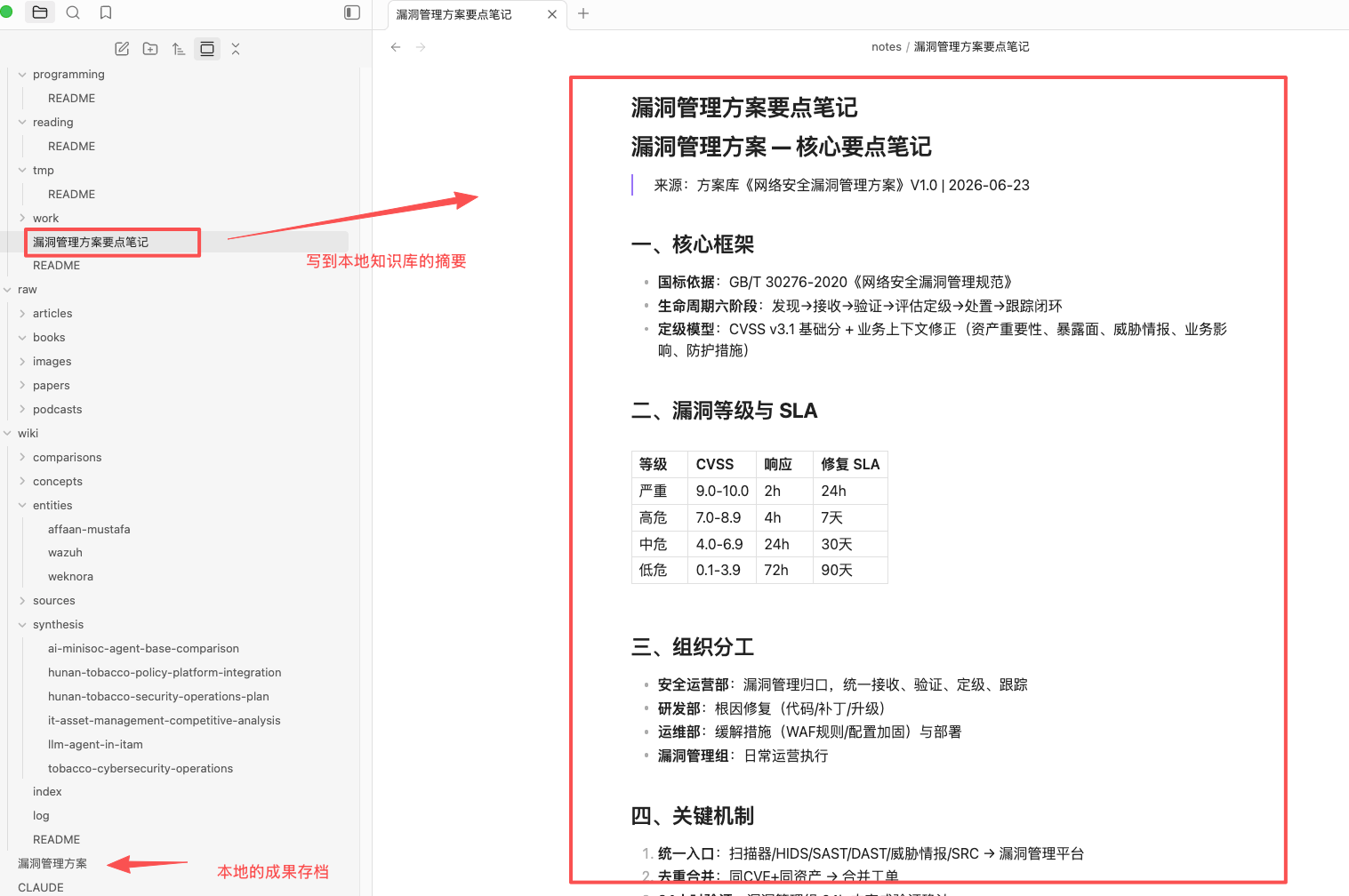
整个过程里,企业库负责权威的、语义检索的素材,本地库负责个人的、可沉淀的积累,云端库负责外部公开资料,Agent 在中间统一调度。 这就是我说的"三库打通"落地后的样子。
八、写在最后
知识库的真正价值,不在于你部署了多强大的引擎,而在于它有没有被真正用起来。
很多人部署完 RAG 平台就束之高阁,因为日常工作时根本想不起来"现在该去查那个库"。scheme-writer 这类 skill 想解决的,就是这个"最后一公里":让用知识库这件事,变成 Agent 的本能,而不是你的额外负担。
而对三类库(本地 / 企业 / 云端)真正的"打通",不在于合并数据,而在于让 Agent 学会用同一套语言操作它们。这件事只有 skill 这种声明式的、可移植的形态能做到——CLI 的 Claude Code 能用,GUI 的 workbuddy 也能用,未来某个新 Agent 出来也能用。
你写一次 skill,换 Agent 不用重学;你接入一次 skill,三类库就用同一套接口管起来。一旦 Agent 学会了自己去查库、归档,你会发现知识库这个东西,终于"活"了。
如果你也在用 Claude Code、workbuddy、Trae Solo 这类支持 skill 的 Agent,又正好有个想用起来的知识库,不妨照这个思路给 Agent 装一个"知识库遥控器"。
相关阅读
- 上一篇:腾讯开源 WeKnora 知识库部署实战(含踩坑排查)
- 下一篇:方案写不出来?用 Claude Code + RAG 打通写方案最后一公里
- WeKnora 项目:https://github.com/Tencent/WeKnora
- scheme-writer 开源:https://github.com/xiejava1018/myopenclaw-skills/tree/master/scheme-writer
如果你也在给 Agent 做知识库 skill,或者想知道某个具体能力的实现细节,欢迎留言交流。
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!